近日,网上流传一份ilya推荐给John Carmack的阅读清单,该清单包含了当今与AI相关27篇顶级文章,并称如果真的将它们读完,就能理解当下90%的AI技术。
下面笔者带大家速览这27篇文章内容概要。
1)Attention Is All You Need

不解释了,transformer开山论文,不得不看。
地址:https://arxiv.org/pdf/1706.03762
2)The Annotated Transformer

该文章是由康奈尔大学副教授 Alexander Rush 等研究者在 2018 年撰写的博客文章 ,该文章对transformer进行了逐行级的解释,并利用 Python 完整实现了 Transformer架构,可以帮助读者在了解理论的同时,结合实践加深认识。
文章:https://arc.net/folder/D0472A20-9C20-4D3F-B145-D2865C0A9FEE
代码:https://github.com/harvardnlp/annotated-transformer/
3)The First Law of Complexodynamics
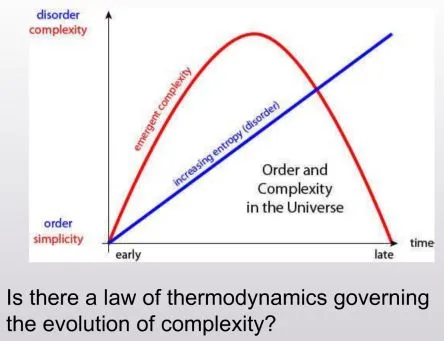
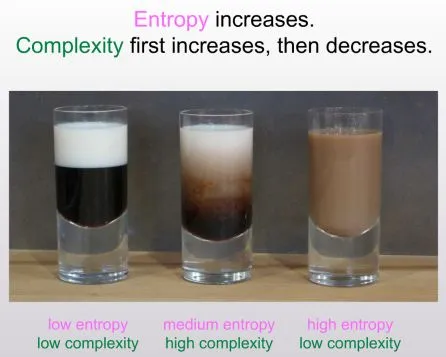
这是Scott Aaronson 的名为《复杂动力学第一定律》的文章,讨论了为什么物理系统的“复杂性”或“趣味性”似乎随着时间的推移而增加,然后达到最大值,再逐渐减少,而熵当然是单调增加的?Aaronson 试图用 Kolmogorov 复杂性和相关概念来解释这一现象,并指出了这一领域的若干挑战和可能的解决方案。
文章:https://scottaaronson.blog/?p=762
4)The Unreasonable Effectiveness of Recurrent Neural Networks(RNN不可以思议的有效性)

该文章是由Andrej Karpathy 2015 年撰写的一篇博客,强调 RNN 的有效性,文章探讨了 RNN 处理序列数据的强大能力。
地址:https://karpathy.github.io/2015/05/21/rnn-effectiveness/5)Understanding LSTM Networks(理解LSTM)
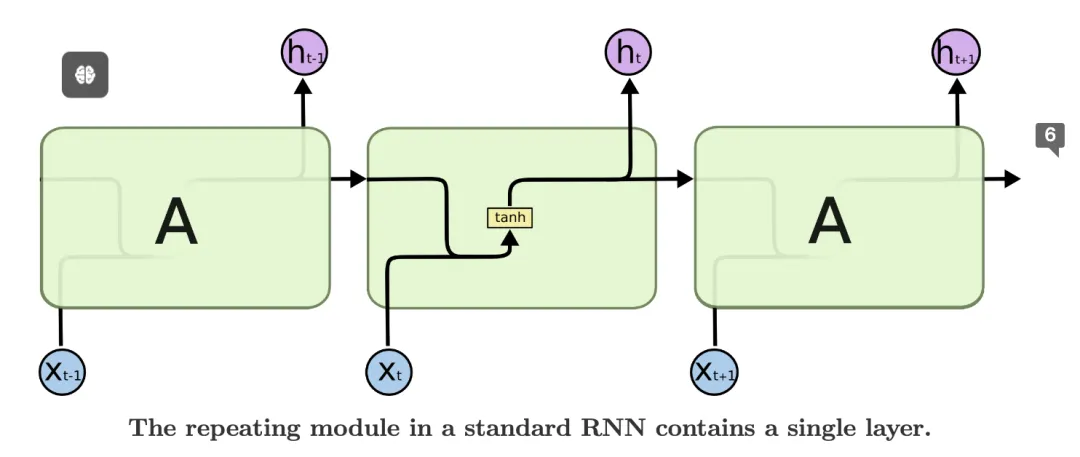
该文由Anthropic 联合创始人、Ilya 和 Christopher Olah 于 15 年撰写,本文介绍了LSTM长短期记忆,它是一种特殊的循环神经网络,能够处理长期依赖关系。它在语音识别、语言建模、翻译、图像描述等领域取得了巨大成功。
地址:https://colah.github.io/posts/2015-08-Understanding-LSTMs/6)RECURRENT NEURAL NETWORK REGULARIZATION(RNN正则化)

本文是由ilya 2015年撰写的,提出了一种递归神经网络的简单正则化技术(RNN)与长短期存储器(LSTM)单元。Dropout是正则化神经网络最成功的技术,但它不能很好地与RNN配合使用和LSTM。在本文中我们展示了如何正确地将dropout应用于LSTM,并表明它大大减少了对各种任务的过拟合。这些任务包括语言建模、语音识别、图像字幕生成,以及机器翻译。
地址:https://arxiv.org/pdf/1409.2329.pdf
7)Keeping Neural Networks Simple by Minimizing the Description Length of the Weights(通过最小化权重的描述长度来保持神经网络的简单性)

如果相较于训练案例的输出向量,权重包含更少的信息,那么有监督的神经网络的泛化能力通常会更好。因此,在学习阶段,惩罚权重的信息量以保持权重简洁是关键。可以通过加入高斯噪声来控制权重的信息量,而且学习过程中可以适应性地调节噪声水平,以达到网络预期平方误差与权重信息量之间最佳的平衡。我们提出了一种方法,可以计算包含非线性隐藏层的网络中,受噪声影响的权重所包含信息量以及期望平方误差的导数。只要输出单元保持线性,就能够高效准确地计算出这些导数,无需依赖于耗时的蒙特卡洛模拟。追求降低神经网络权重传输所需信息量的理念催生了许多有趣的权重编码方案。地址:https://www.cs.toronto.edu/~hinton/absps/colt93.pdf8)Pointer Networks

论文引入了一种新的神经网络架构,该架构旨在学习输出序列的条件概率,其中输出序列由代表输入序列位置的离散Token(代币)组成。现有的方法,如序列到序列转换 和神经图灵机,无法轻易解决这类问题,因为输出序列中每一步的目标类别数依赖于可变的输入长度。例如,排序可变长度序列和各类组合优化问题都属于这种问题。我们的模型利用最近提出的神经注意机制解决了可变长度输出字典的问题。与以前的注意力机制不同,我们的方法不是将注意力用于融合编码器的隐藏单元到每个解码步骤的上下文向量中,而是将注意力用作一个指针,选取输入序列中的元素作为输出。我们将这种架构称为指针网络(Ptr-Net)。通过只使用训练实例,我们证明了Ptr-Net能够学习到三个复杂几何问题-计算平面凸包、Delaunay三角剖分以及平面旅行商问题-的近似解。Ptr-Net不仅改进了带输入注意力的序列到序列模型,还实现了输出字典规模可变性的泛化。我们进一步展示了,这些学习到的模型能够泛化到超出训练时的最大长度。我们希望这些任务上的结果能鼓励对离散问题的神经网络学习方法进行更深入的研究。
地址:https://arxiv.org/pdf/1506.03134
9)ImageNet Classification with Deep Convolutional Neural Networks

本文图灵奖得主 Geoffrey Hinton ,ilya等撰写,提出 AlexNet,颠覆图像识别领域,开启了深度学习革命。他们训练了一种庞大的深度卷积神经网络来对ImageNet LSVRC-2010竞赛的1.2百万张高清图像进行分类,这些图像被分为1000个不同类别。在测试数据集上,实现了37.5%的top-1错误率和17.0%的top-5错误率,显著优于之前的最佳水平。该神经网络拥有60,000,000个参数和650,000个神经元,由五个卷积层组成,部分卷积层后接最大池化层,还包括三个全连接层以及最后的1000维softmax输出层。为了加快训练速度,采用了非饱和神经元以及高效的GPU卷积操作实现。此外,为了降低全连接层的过拟合,采用了一种名为“dropout(随机失活)”的新近开发的正则化技术,这一技术非常有效。在ILSVRC-2012比赛中提交了这个模型的改进型,并以15.3%的top-5测试错误率赢得了冠军,较第二名低了10.9个百分点,这表明了模型的显著提升。
地址:https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
10)ORDER MATTERS: SEQUENCE TO SEQUENCE FOR SETS

随着循环神经网络的兴盛,序列在有监督学习中越发重要。现在,许多复杂的任务,如映射观察序列,都可以通过使用序列到序列转换(seq2seq)框架来构建,该框架采用链式法则高效表示序列的联合概率。但在某些情况下,可变长度的输入/输出并不适合以序列形式表现。比如,对于排序任务,还不清楚如何把一组数字输入模型;相似地,当任务涉及建模随机变量的未知联合概率时,我们也不知道应如何组织输出。在这篇论文中,我们首先通过多个例子证明了输入/输出数据组织顺序对学习底层模式的显著影响。我们接着探讨了seq2seq框架的一种扩展,它能够超越序列处理,按照原理性的方法处理输入集。另外,我们提出了一种损失函数,它通过在训练过程中探讨不同的数据序列,解决输出集合结构缺失的问题。我们提供了关于订单重要性的实证证据,并展示了在语言建模和解析任务的基准测试,以及两个人造任务——数字排序和估计未知图模型的联合概率上对seq2seq框架所做的修改。
地址:https://arxiv.org/pdf/1511.06391
11)GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism

该论文介绍了 GPipe,一个模型并行库,允许通过微批次管道并行化来扩展大型神经网络的容量,在图像分类和多语言机器翻译任务上展示了其应用。提升深度神经网络的计算容量已证明是提高多种机器学习任务中模型性能的有效办法。然而,在很多情况下,增加模型的计算力以超越单个加速设备的内存限制,通常需要开发专门的算法或基础架构。这些方案往往依赖于特定的硬件架构,且难以应用于其他任务。为了应对这种对于高效且与任务无关的模型并行性需求,文中介绍了GPipe,这是一个实现流水线并行化的库,它能使任何可以表示为层序列的网络进行规模化扩展。利用GPipe,通过在不同加速设备上对不同的层子序列进行流水线作业,可以灵活且高效地扩大各种网络的规模至巨大程度。此外,GPipe采用了一种创新的批处理分流算法,在将模型分配到多个加速设备时,几乎可实现线性的加速效果。通过在具有不同网络架构的两项不同任务上训练大规模神经网络来展示GPipe的优势:一是图像分类,训练了一个参数量达到5.57亿的AmoebaNet模型,在ImageNet-2012数据集上获得了84.4%的top-1准确率;二是多语言神经机器翻译,训练了一个包含128层Transformer结构、6亿参数量,覆盖超过100种语言的巨型模型,其表现超越了所有双语模型。














暂无评论内容