
文 | 王乙雯 瞭望智库
这两天,AI领域的进展又让人惊呼“炸裂”。
先是5月14日,美国开放人工智能研究中心(以下简称OpenAI)发布了最新多模态大模型GPT-4o,没有以往对指标提升的生硬强调,而是选择集中展示多种场景下的用户体验。结果体验下来,GPT-4o的反应速度、情感表达和理解能力与真人无异,让看了发布会的观众们久久未从震撼中走出,直呼这就是“人类最理想AI语音助手的样子”。
紧接着第二天,谷歌又端上“AI全家桶”迎面反击,不仅有对标GPT-4o的全能AI助手Project Astra,还有对标Sora的视频生成模型Veo等一系列推新和升级,快两个小时的发布会,谷歌CEO桑达尔·皮查伊整整提了120次AI。
眼看AI丝滑如真人,人们震撼不已,又焦虑四起。GPT-4o们到底厉害在哪?AI大模型加速进入应用“深水区”?老师、翻译要失业?库叔和《生成式人工智能》作者、美国俄亥俄州立大学人工智能专业博士丁磊聊了聊,他为我们带来了专业视角的思考和启发。
让我们先从GPT-4o的表现看起。
1
“her”来了
GPT-4o的取名可见其深意,O代表“Omini”,意思是无所不能的。从现场表现来看,它也算是“o如其名”了。
首先是实时语音对话,GPT-4o加持下的新ChatGPT不仅无缝接梗,情绪价值也直接拉满。比如,研发负责人Mark Chen表示自己因为上台紧张,ChatGPT便温柔地鼓励道:“你在台上做演示吗?那你真的太棒了!深呼吸一下吧,记得你是个专家!”而Mark表示要再来个深呼吸,ChatGPT顺势接话“慢慢呼气”,紧接着Mark一边疯狂地大喘气,ChatGPT惊讶地说:“放松啊Mark,慢点呼吸,你可不是个吸尘器!”
过程中,模型的反应时间已经缩短至平均320毫秒,并且它还能理解人类在对话中适时“打断”的习惯,会及时停下来听你说话并给出相应回复,也不会“断片”。这反应速度已达到人类级别。
和人一样的,又何止是速度。Mark让它讲睡前故事,并“作精”上身疯狂要求加戏,“多点情绪,再抓马(drama)一点行不?”“不行不行,再多点情感”,多次打断不断加码后,ChatGPT的声音如演莎士比亚戏剧般开始压低着呐喊,Mark又话锋一转,“唱个歌吧”,于是,现场竟听到了ChatGPT无奈叹了一口气。真是脾气好好的一个“人”啊!
不仅如此,人们可以任意上传文本、音频、图像,也可以打开手机摄像头,与它随时讨论和互动,GPT-4o的表现也是十分出色。
比如讲数学题,GPT-4o就扮演了一名教师,实时语音指导着男孩完成了数学题的解答。全程耐心十足,在GPT-4o一步步鼓励和引导下,男孩顺利推导出正确答案,现场堪比网课1v1辅导,家长血压保住了。
再比如翻译,它不仅可以准确地进行50种语言的实时交互翻译,还可以通过摄像头识物,来进行外语单词的教学。

同样利用GPT-4o模型,OpenAI和Be My Eyes合作推出了一款APP,可以帮助视力受限人群实时了解身边场景,并提供帮助。他们只要举着手机,就可以“看见”路上和周边的一切。比如路上行驶的出租车是否处于空车状态,提示视力受限人士招手打车,以及车辆是否已经停下。

以上,用户可以任意组合输入文本、音频、图像,也可以得到ChatGPT实时文本、音频、图像的任意组合输出,GPT-4o展现出的多模态能力令人印象深刻。
OpenAI首席执行官萨姆·奥尔特曼(Sam Altman)在X上发了一个简短的词:“her”。对,就是科幻电影《Her》中的语音智能助手Samantha,已经由OpenAI接近于完成。

网友制作的电影《Her》海报(右图),男主的脸换成了奥尔特曼的脸。来源:网络
《生成式人工智能》作者、美国俄亥俄州立大学人工智能专业博士丁磊在接受瞭望智库采访时表示,“根据OpenAI的说法,GPT-4o是一个真正的跨模态大模型。包括视觉、音频等的输入输出,都是由一个统一的模型框架来处理的。”丁磊介绍:“原来我们是需要先进行语音识别,转录成文本,然后文本进行回答再合成语音,这样效果就不尽如人意,而现在通过跨文本、视觉、音频端到端的训练这么一个融合大模型,就会感觉到在语音模式下输入输出变得更加灵敏,更符合人感官的要求。”
“它(GPT-4o)的多模态自然交互能力,包括对图文的理解都比较强,是否预示着GPT-5的部分功能被选择性地发布出来,让公众先做一个体验?是有这种可能的。”丁磊推测。
除了拥有多种模态的能力,GPT-4o的推出还有一个亮点——免费,但是有使用限额。而付费用户的消息限额将比免费用户高出5倍。据悉,GPT-4o将在未来几周内分阶段集成至OpenAI的各个产品中。
其实,不止OpenAI,AI领域内多家公司多模态大模型应用的探索也都有所布局。
2
谷歌反击,端上“AI全家桶”
Open AI发布GPT-4o的第二天上午,谷歌在自己的 I/O 大会上发布了一系列基于Gemini的“AI全家桶”。包括升级200万tokens上下文的Gemini 1.5 Pro(这意味着,用户可以输入2小时视频、22小时音频、超过6万行代码或者140多万个单词)、新模型Gemini 1.5 flash、类Sora的新视频大模型Veo,以及包括AI搜索、AI + Gmail在内的多个AI应用。
其中,Veo 是谷歌DeepMind目前最强的生成式视频模型。这个新工具配备了一个故事板模式,可以逐个场景地进行迭代,并向最终视频添加音乐。谷歌高管称,Veo能理解“延时拍摄”等电影术语,可以生成各种电影和视觉风格的 1080p 分辨率的视频,时间还可以超过60秒。
当然,还有被拿来直接和GPT-4o对比的万能助手项目Project Astra。据介绍,Project Astra是一个实时、多模式的人工智能助手,通过接收信息、记住它所看到的内容、处理该信息和理解上下文细节来与周围的世界进行交互,可以回答问题或帮助人们做事情。
演示视频中,用户要求Project Astra在看到发出声音的东西时告诉她,助手回答说,它可以看到一个发出声音的扬声器。用户还问了Project Astra屏幕上的代码有什么作用,几乎没有停顿,就得到了AI助手流畅的解释。
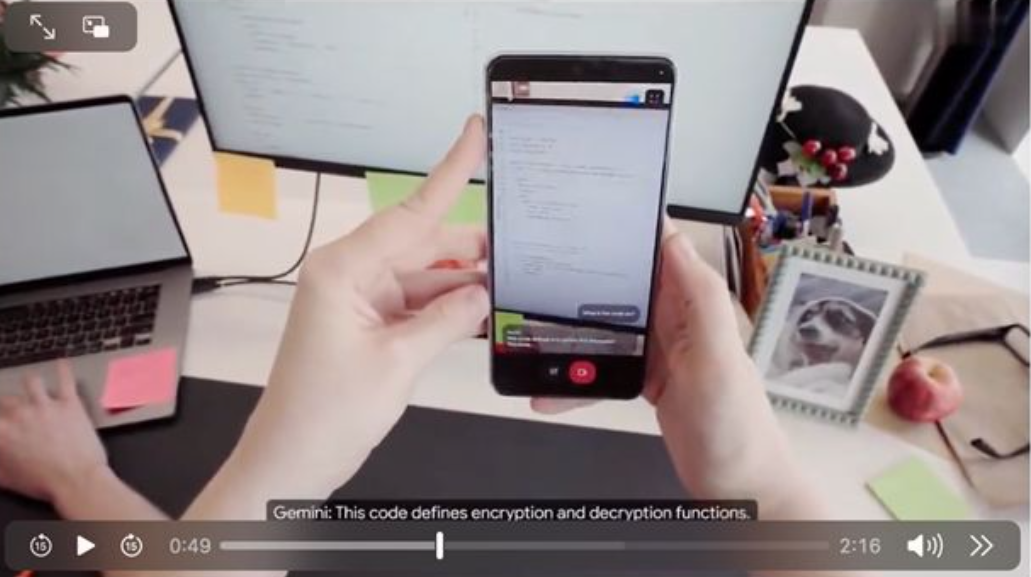
Project Astra演示视频截图
甚至在不经意间,Project Astra还展现了它的记忆力。用户问:“你记得我把眼镜放哪了吗?”助手答道,“你的眼镜在桌子上的红苹果旁边。”可以看到,Project Astra通过镜头记住了一闪而过的眼镜。

Project Astra演示视频截图
有媒体总结指出,这次I/O 大会上,谷歌重点强调了大模型的多模态和长文本能力。技术的进步使Google Workspace等生产力工具变得更加智能化。例如,我们可以要求 Gemini 总结一下学校最近发来的所有电子邮件。它会在后台识别相关的Email,甚至分析 PDF 等附件。随后你就能获得其中的要点和行动项目的摘要。
另外,谷歌还在大模型Agent(智能体)上看到了更多的机会。利用Agent 的应用能够提前“思考”多个步骤,并跨软件和系统工作,更加便捷地帮你完成任务。这种思路已经在其搜索引擎等产品中得到了体现。
腾讯研究院副院长刘琼曾在某次论坛上介绍过Agent,他说:“Agent是大模型未来在行业落地中的一个重要应用形态,在从任务到工作的终极目标中,Agent真正能替代人形成新的生产力。其次,Agent是连接大模型和现实世界,包括许多应用和现实问题的‘最后一公里’。Agent具备自我决策和学习能力,以及规划、记忆和可扩展工具的能力,使其在特定领域具有无限发展潜力。”
3
谁又慌了?
每每有AI新技术和产品发布,就能看到有人惊呼“硅基生命将取代碳基生命”“AI接管人类社会”。人们普遍担心的,就是AI对原有的工作的冲击。
据报道,国际货币基金组织总裁克里斯塔利娜·格奥尔基耶娃近日表示,未来两年,对于发达经济体而言,人工智能可能会影响60%的工作岗位;而对于全球所有国家而言,人工智能可能将冲击40%的工作岗位。
丁磊认为,目前各种生成式AI模型仍在研发阶段,还有待进一步落地应用,谈论是否能取代人类的工作还为时过早,但AI的影响力不可否定。因为AI带来的改变是深入各行各业和我们生活的每个角落的。
关于人工智能对人力可替代性,丁磊认为可以从三个方面去分析,分别是社交智慧、创造力、感知和操作能力:
社交智慧指的是人和人交互的技能,包括同理心、谈判能力、社交洞察力等情感能力,对应的职业主要是教师、销售、心理咨询师、 管理人员、社工等;
创造力指的是原创能力和艺术审美能力,对应的职业主要是艺术家、作家、研发工程师等;
感知和操作能力指的是手指灵敏度、协调操作能力和应付复杂工作环境的能力,包括专业能力、行业经验、工作效率、完成效果等,对应的职业主要是律师、医生、司机、美发师、急救人员、电工等。
人工智能在处理不面对人、创新性和变通性较低的工作时,效率更高、稳定性更好,而面对需要情感交互、相对复杂场景或者需要创新性较高的工作时,就表现得不那么令人满意了。
“与其说AI将取代从业者,不如说AI代替的是枯燥繁重的工作内容,AI淘汰的不是人类,是落后的生产力”,丁磊说,AI的发展同时带来的,还有新兴职业和岗位的出现,比如AI产品经理、提示词(Prompt)工程师、AI创意师、AI 调校师等等,这些职业的需求和数量也将逐步提升。
丁磊表示:“对于AI,我们不应该将其视为竞争对手,而是将其视作我们的工作伙伴,训练并加以使用。正所谓,君子生非异也,善假于物也。”
4
未来,大模型会走向何处?
回到AI 产业,可以说,在产品中创造价值是一种共识。
“在产品里的价值创造这方面,我个人觉得OpenAI可能比大公司做得更好一些。”丁磊认为,OpenAI跟谷歌就是创业公司跟大公司的区别,“从现在的整个形势上来看,很多时候OpenAI反而是领先者,谷歌等大公司是追赶者”。
丁磊告诉瞭望智库,无论是Transformer还是Instruction Tuning等算法模型,这些其实都不是Open AI首创的,但它不因为是别人发明的就避之不用。而是秉承“拿来主义”,持续在自己的大模型里埋首用功,不断提升产品和用户的体验。
在研发和创新上,还有一个关键因素是模式不同。“这些大公司还是按照原有的软件研发方式研发新的AI技术,将任务拆成不同的细分任务,多部门人员各自负责细分业务,是一种‘养鸡模式’。而以大模型训练为核心的新兴AI技术研发,其本质是一个很难拆解的任务,需要核心领导层在技术、产品和业务等层面都有端到端的视野和管控能力。这更像是一种‘养娃模式’,父母需要站在全局角度去教授和培养孩子,也就是说,孩子的教育不需要那么多老师,核心人物只要少数。根据OpenAI发布的Sora技术报告,Sora作者团队仅有13人。”这次GPT-4o发布会后,奥尔特曼表扬了关键团队成员,报道显示,Omni团队成员仅有17人。
未来,大模型还会走向何处?
丁磊认为,多模态是一个大的方向。“包括自然交互,这些其实都是面向C端(消费者)服务的。”他特别指出,AI和行业应用的落地也是非常重要的环节。“如果把大模型真正跟行业结合,我觉得可能更需要结合类似于‘世界模型’这样的概念。怎么在行业里落地,就需要大模型能具备行业的知识,目前很多公司都是刚刚开始做。”
在具体领域的大模型应用中,由谷歌DeepMind和Isomorphic Labs团队研发的最新迭代人工智能模型AlphaFold3就颇具代表性。以前所未有的精确度成功预测了所有生命分子(蛋白质、DNA、RNA、配体等)的结构和相互作用。与现有的预测方法相比,AlphaFold 3 发现蛋白质与其他分子类型的相互作用的准确率至少提高了50%,对于一些重要的相互作用类别,预测准确率甚至提高了一倍。
无论是全能助手,还是行业利器,对于AI应用的发展,人们在期待中也有担忧。在业内,也不乏呼吁暂停研发的声音。“目前行业对于巨型AI怎么应用,还没有准备好,可能会产生一些担心。其次可以推测,这其中不乏可能有一些商业利益的考虑,比如说我没造出来,你也别造。”
正如丁磊所说,“对社会而言,我们要做到科技向善。因为技术的发展一定程度上是很难停滞的,尤其是提升生产力的技术,很难去暂停它的发展。”
参考资料:
1.OpenAI一夜改写历史,GPT-4o干翻所有语音助手,丝滑如真人|新智元.2024.05.14
2.谷歌反击:Project Astra正面硬刚GPT-4o、新版Gemini变革搜索|机器之芯pro.2024.05.15
3.革命性进展?诺奖级发现?“阿尔法折叠3”是重磅创新还是版本升级|文汇报.2024.05.11
4.丁磊:直面Sora,拒绝胡扯!|中信出版集团.2024.02.28
5.环球时报专访AI业内人士:发展人工智能,中美各有什么“长短板”|环球网.














暂无评论内容