多模态大模型,也有自己的CoT思维链了!
厦门大学&腾讯优图团队提出一种名为“领唱员(Cantor)”的决策感知多模态思维链架构,无需额外训练,性能大幅提升。

在 ScienceQA 上,基于GPT-3.5的Cantor准确率达到了82.39%,相比基于GPT-3.5的思维链方法提升了4.08%。
在更具挑战性的MathVista上,基于Gemini的Cantor准确率比原始Gemini提高了5.9%。
目前Cantor论文已上传arXiv,代码也已经开源。
多模态专属思维链
思想链(Chain-of-Thought, CoT)是一种广泛应用的提示方法,通过添加中间推理步骤,可以显著增强大模型的推理能力。
然而,在视觉推理任务中,模型不仅需要把握问题背后的总体逻辑,还需结合图像信息进行具体分析。
多模态思维链应运而生。
现有的多模态思维链方法通常将问题分解为多个相关的子任务,并调用各种外部工具依次处理。
然而,由于视觉信息不足和低级感知工具的局限性,这种范式在决策中面临潜在的“决策幻觉”,以及低级感知工具无法提供高级推理信息的挑战。
Cantor架构赋予多模态大语言模型(MLLM)或大语言模型(LLM)像合唱团中的领唱员一样的协调能力:
首先使MLLM或LLM同时处理视觉和文本上下文,形成全面的理解并进行决策感知,避免决策幻觉。
随后,将具体任务分配给MLLM 扮演的“专家”,以获得高级的认知信息以进一步辅助推理。
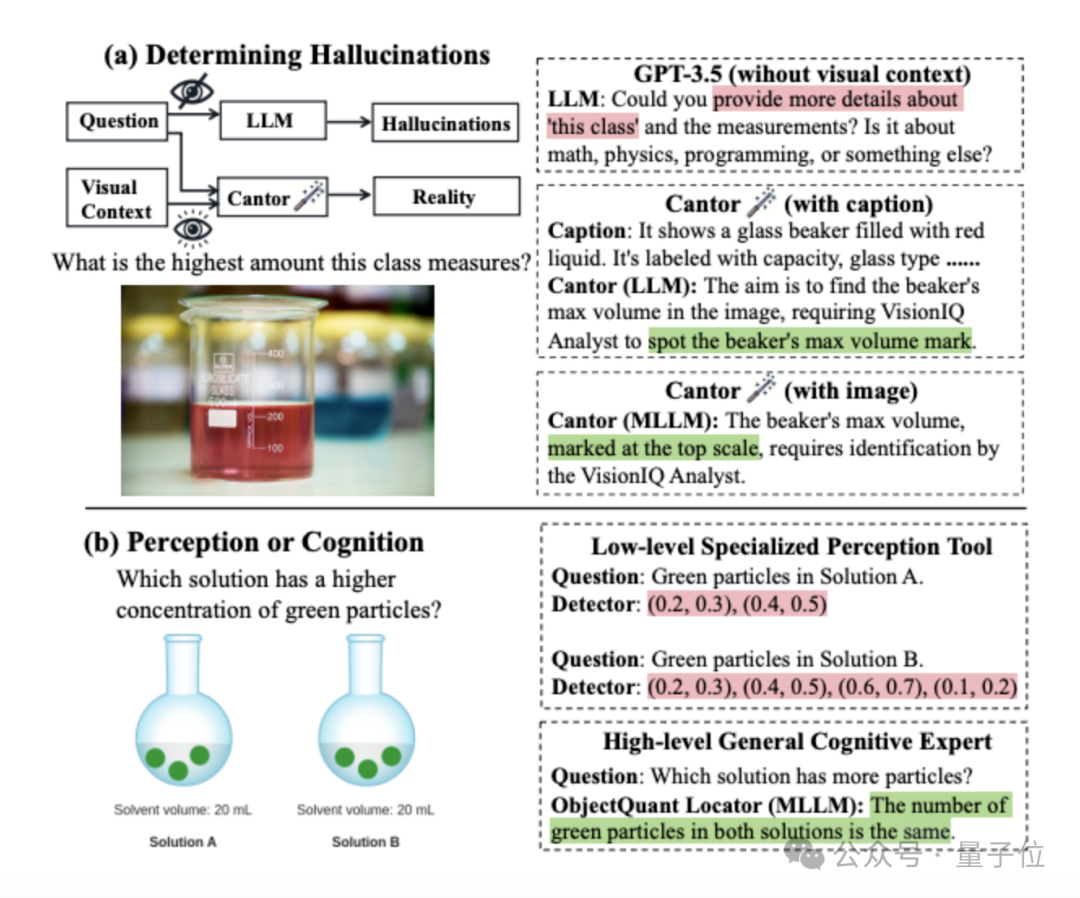
图中(a)展示了不同视觉信息对决策的影响:
- 在没有视觉上下文的情况下,询问GPT-3.5烧杯的最大刻度,会由于缺乏图像信息而无法回答,出现决策幻觉,要求提供更多信息。
- 基于LLM的Cantor通过字幕引入了视觉语境,避免了决策幻觉,提出了合理的解决方法。
- 基于MLLM的Cantor通过图像加强了视觉语境,进一步提高了决策质量,将子任务具体化。
图中(b)展示了不同视觉工具的比较:
- 对于目标检测相关的子任务,传统方法使用的低级感知工具(如检测器)只能获得基本数据(如坐标)。这些低级线索需要后续的进一步整合才能得到有用信息,这会增加推理负担。
- 由MLLM扮演的高级认知专家可以直接获得高级推理信息(如目标的相对数量关系),有助于后续推理。
决策生成+执行两步骤
Cantor的架构如下,它包含两个主要步骤:决策生成和执行。
前者对问题进行分析与解耦,结合各种专家模块特性,生成合理的决策。
后者调用各种专家模块执行子任务,并汇总信息加以思考,生成最终答案。
团队具体设计了四种专家模块:
- TextIntel Extract:此模块会按要求针对性地提取图像中的文本。它对于包含文本和图形元素混合的图像特别有用。
- ObjectQuant Locator:此模块用于识别并定位图像中的对象。它在比较数量和识别空间关系等方面有优势。
- VisionIQ Analyst:此模块用于处理和解释视觉数据,它能够处理任何与图像内容相关的查询,善于分析图像。
- ChartSense Expert:此模块专门分析和解释图表中的信息。它可以提取数据点,了解趋势,并识别图表中的标题、轴、标签和图例等关键组件。
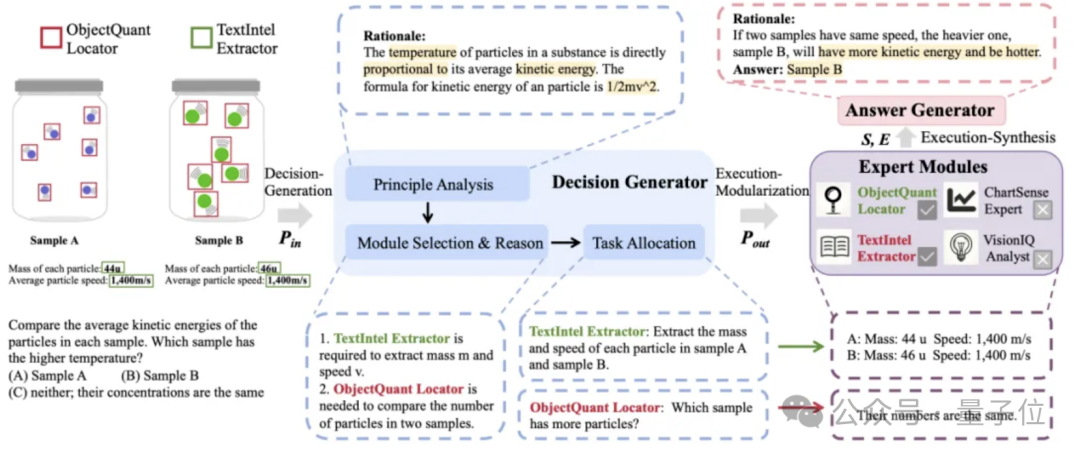
决策生成部分让MLLM或LLM扮演决策生成器,也就是充当决策大脑,先对问题进行分析,并结合各专家模块特点,分配子任务,并给出分配理由。
例如要比较两瓶溶液的温度大小时,Cantor会先分析粒子温度与粒子动能的关系,分析粒子动能的表达式为1/2mv^2。并结合图像信息与专家模块特点,为TextIntel Extractor和ObjectQuant Locator分别分配子任务:
1、提取样品A和样品B中每个颗粒的质量和速度。
2、哪个样品的粒子数量更多?
该步骤有以下特点:
最初,LLM或MLLM被用作决策生成器,充当决策的大脑。
接下来,团队提供多个专家模块,以完成各种类型的子任务,充当决策的四肢。这种集成确保了决策生成既全面又精细,能够充分利用了每个模块的优势。
此后,决策生成器根据从原理分析中获得的见解,为选定的专家模块量身定制任务,这种动态的任务分配提高了Cantor的效率和性能。
执行又分为模块化执行和汇总执行两步:
一是模块化执行:
在这个阶段Cantor通过调用各种专家模块来完成决策生成阶段分配的子任务,以获得补充信息。
值得注意的是,团队只使用MLLM来扮演各种专家模块,以获得高级的认知信息辅助推理(如数量的大小关系,位置的相对关系)。
例如,对应上一步分配的子任务,TextIntel Extractor和ObjectQuant Locator分别获得以下答案:
1、样品A:质量44u,速度1,400m/s。样品B:质量46u,速度1,400m/s。
2、两个样品的粒子数量相同。
二是汇总执行:
在这个阶段Cantor汇总子任务和子答案的信息,并结合基本原理,生成最终答案。
其中包括了三个关键,首先通过提示,让MLLM或LLM扮演一个知识渊博并且善于整合信息的答案生成器,这既保证他的专业性,能对问题有基本判断,又保证他能更好地整合信息。
其次为了可解释性,展示模型的思维过程并提高其思维能力,要求它先生成为答案的基本原理,然后生成相应的选项。
最后要求Cantor保持理性与批判性,不要完全依赖模块执行获得的信息。
免训练也能超越微调方法
Cantor分为两个版本,Cantor(GPT-3.5)将GPT-3.5作为决策生成器和答案生成器,以及Cantor(Gemini)将Gemini Pro 1.0作为决策生成器和答案生成器。
团队在ScienceQA和MathVista两个复杂的视觉推理数据集上进行了实验。
在ScienceQA上的实验结果如下:
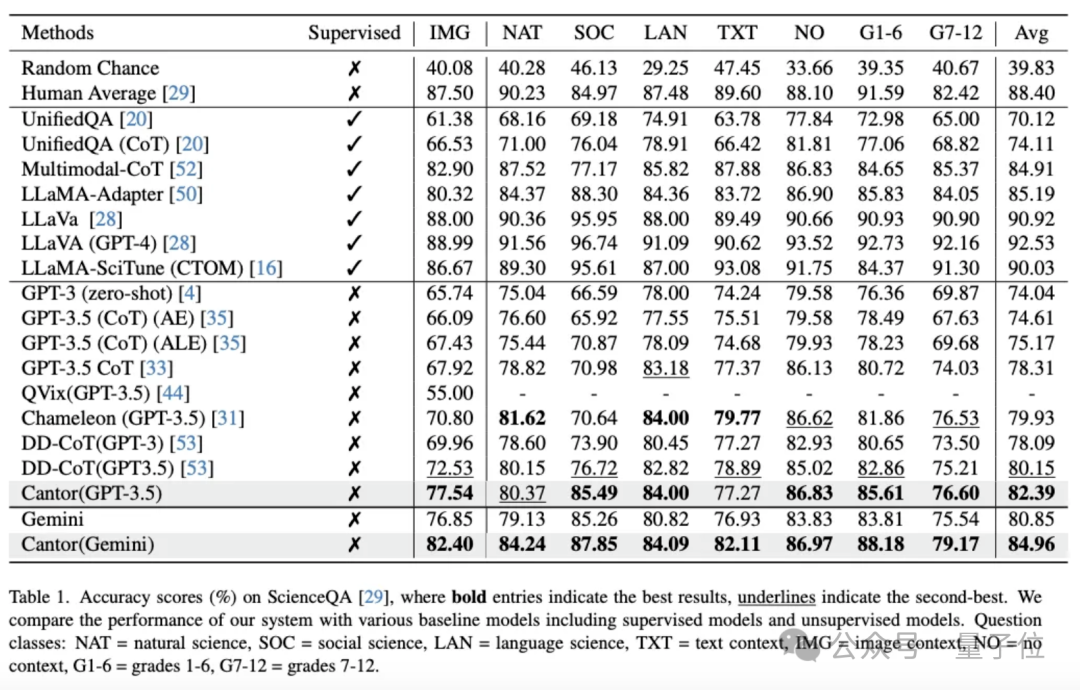
结果显示使用GPT-3.5作为基本LLM进行决策和回答,Cantor的准确率达到82.39%,比GPT-3.5提示的思想链(CoT)提高了4.08%。
使用Gemini作为决策生成器和答案生成器,Cantor的准确率达到84.96%,大大超过了所有免训练方法,甚至优于UnifiedQA(CoT)和MM-CoT等微调方法。
团队进一步展示了ScienceQA中IMG类的性能,该类的所有问题都包括了图像上下文。

可以看出,基于GPT-3.5的Cantor在各种问题上都显著超过了基线,甚至超过了一些著名的MLLMs,如SPHINX和LLaVA-1.5。
Cantor(Gemini)性能相比于基线也得到了显著增长。

MathVista是一个具有挑战性的数据集,它将各种数学推理任务与可视化任务集成在一起。
上表比较了不同方法的性能。从一般的视觉问题回答到专业的数学问题,Cantor在几乎所有类型的问题中都大大超过了基线。
这表明,正确的决策和模块化专家可以激发他们细粒度、深入的视觉理解和组合推理能力。
值得注意的是,Cantor(GPT-3.5)甚至超过了基于CoT和PoT的GPT-4。
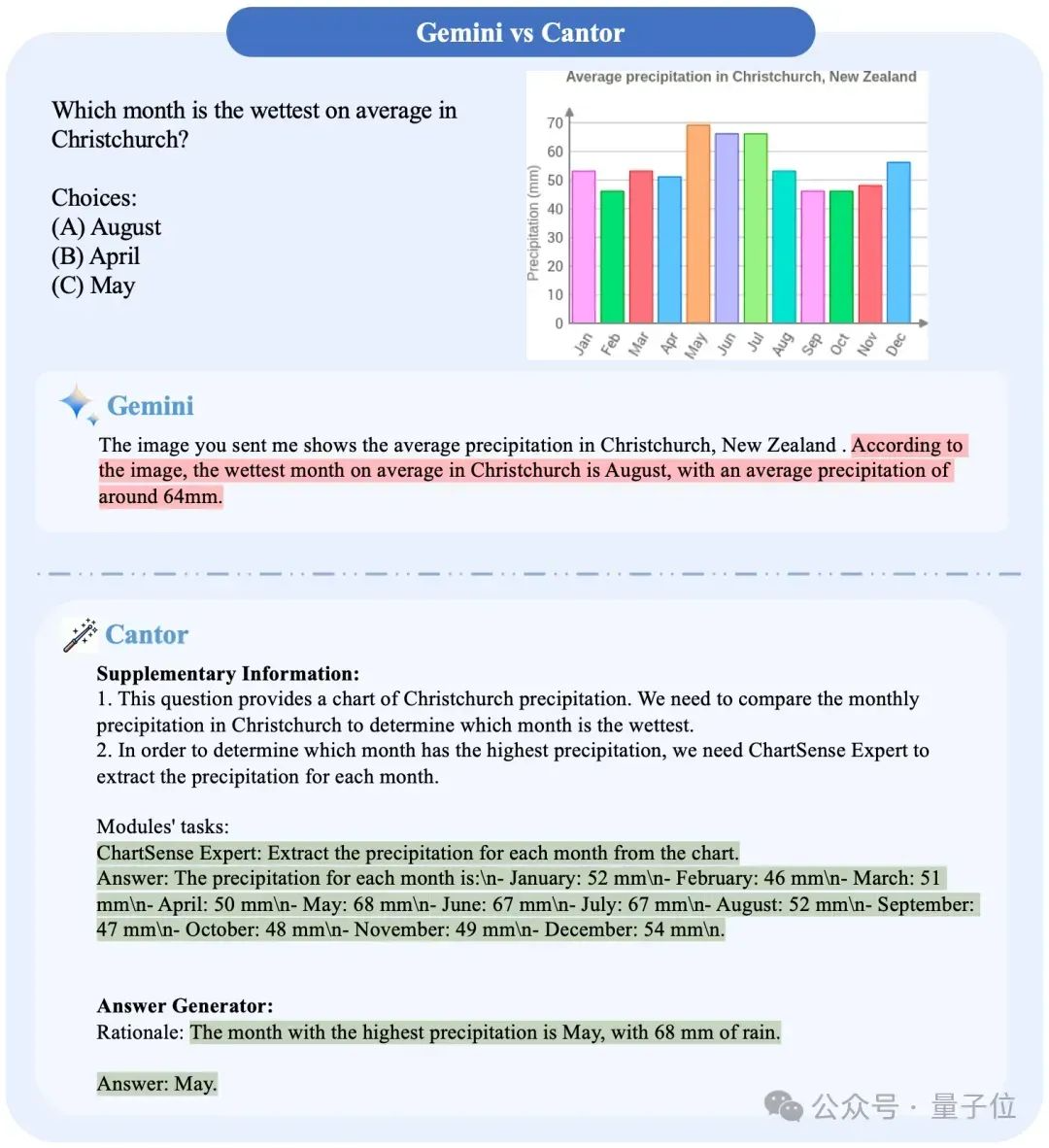
团队进一步展示了Gemini与Cantor(Gemini)的具体例子比较:
可以看出Cantor通过任务分配,以及让Gemini进行角色扮演,做到了原来难以做到的事情,并且正确得出了答案。
值得注意的是,即使Gemini在一些问题上答对了,但是它的推理过程其实是有问题的,相比之下Cantor没有出现这个问题。















暂无评论内容