代码生成可以说是大模型应用中效果最好,使用人群最广的一项任务了。
但是由于编程语言众多,要应对各种不同的边缘场景,代码生成任务又是对模型能力要求最高的任务,一般的自然语言提示,甚至是CoT等方法,对于代码生成任务来说,效果也不是很好。
但是最近在GitHub上有一个项目大火,它通过一系列针对大模型代码生成任务的优化,将提示词工程升级为一个更加复杂的「流程工程」,能够大幅提升模型输出的代码质量。
项目地址:https://github.com/Codium-ai/AlphaCodium
就连AK看了,都很兴奋地转发,认为如果代码生成任务能够以更科学的流程,而不是简单的问答方式来和大语言模型互动的话,性能确实还有不少提升的空间。
作者把这个项目称为AlphaCodium ,一种基于测试的、多阶段、面向代码的迭代流程。
他们在由谷歌DeepMind提出的一个非常有难度的代码测试集CodeContests上进行测试,将GPT-4的成绩从19%提高到了44%。
由于CodeContests代码生成问题的复杂性,简单的提示优化,甚至CoT提示,无法获得有意义的性能提高。
最主要是因为就算强如GPT-4,也难以理解和「消化」问题,会不断产生错误的代码。
适用于自然语言任务的通用流程可能不适用于像CodeContests上这种有难度代码生成任务。
CodeContests数据集
CodeContests是Google Deepmind推出的一个具有挑战性的代码生成数据集,其中包括了很多像Codeforces等竞赛性编程平台编写的问题。
这个数据集包含约一万个可用于训练LLM的问题,以及用于评估LLM解决具有挑战性的代码生成问题的能力的验证和测试集。
作者没有训练专用模型,而是开发了一个面向代码的流程,这个流程可以应用于任何能够用于编码任务的预训练的LLM,例如GPT或DeepSeek。
下图展示了一个 CodeContests 数据集中的典型问题示例:

为什么CodeContests是一个评估代码生成任务的LLM的优秀数据集?
主要原因是:
1)CodeContests与许多其他竞争性编程数据集不同,它利用一套全面的不公开的测试来避免错误检测——每个问题包含约200个生成的代码解决方案,输出和输入都要通过这个测试。
2)LLM通常不擅长关注小细节,因为他们通常会将问题描述转换为某种「平均」描述,接近于模型接受训练时的常见案例。
另一方面,现实世界的问题经常包含正确解决问题内容中至关重要的小细节。
CodeContests 数据集的一个关键特征是,问题描述在设计上是复杂而冗长的,并且存在一些小细节和细微差别(参见上图中的典型问题描述)。
作者认为增加这种问题理解的自由度是有益的,因为它能真实模拟现实生活中的问题,这些问题通常很复杂,涉及多种因素和考虑因素。
这与更常见的代码数据集(例如 HumanEval)形成对比。

作者认为适当的自我反思会使问题更加清晰、更加连贯。这说明了问题理解作为流程的一部分的重要性,它很可能导致正确的代码解决方案。
为了应对这种和现实问题很接近的测试集,作者提出了这样一个流程:
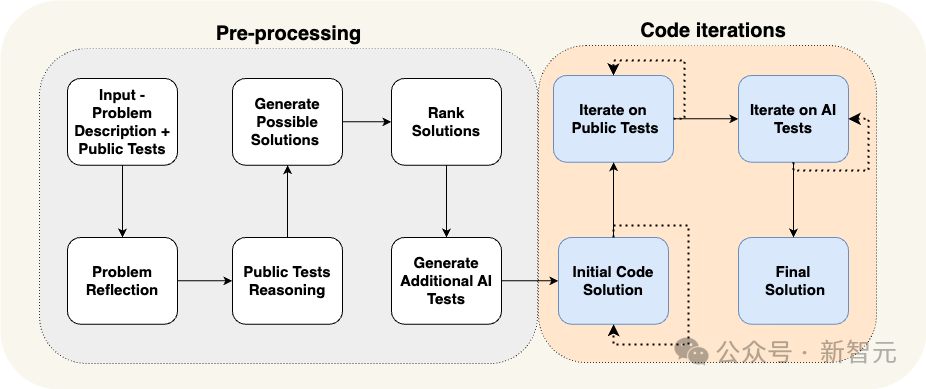
该流程主要是一个迭代过程,作者根据输入输出测试反复运行和修正生成的代码。
这种以代码为导向的流程有两个关键要素:
- 预处理阶段是一个线性流程,用自然语言对问题进行推理。在预处理阶段生成额外的数据,如自我反省和公共测试推理,以帮助迭代过程;
- 代码迭代阶段包括根据特定测试生成、运行和修复代码的迭代阶段。这个阶段使用人工智能生成的额外测试来丰富公共测试。
面向代码的设计理念
AlphaCodium 流程广泛使用了以下设计概念:
YAML 结构化输出
结构化输出的使用——要求模型生成 YAML 格式的输出,相当于给定的 Pydantic 类——是我们提出的流程中的关键组件。此类指令的示例:
…Your goal is to present possible solutions to the problem.Make sure that each solution fully addresses the problem goals, rules, and constraints.
The output must be a YAML object equivalent to type $PossibleSolutions, according to the following Pydantic definitions:
class Solution(BaseModel): name: str = Field(description=”The name of the solution”) content: str = Field(description=”A description of the solution”) why_it_works: str = Field(description=”Why this solution is correct. Be specific and detailed regarding the problem rules and goals”) complexity: str = Field(description=”The complexity of the solution”)
class PossibleSolutions(BaseModel): possible_solutions: List[Solution] = Field(max_items=3, description=”A list of possible solutions to the problem. Make sure each solution fully addresses the problem rules and goals, and has a reasonable runtime – less than three seconds on a modern computer, given the problem constraints for large inputs.”)
结构化输出消除了「提示工程」所需的大部分麻烦和黑暗知识,而是允许以简单的、类似代码的方式呈现复杂的任务。它还使得获得涉及多个阶段的复杂答案成为可能,代表逻辑和有条理的思维过程。
要点分析
当要求 LLM 推理问题时,要求输出采用要点格式通常会获得更好的结果。
要点鼓励对问题的深入理解,并迫使模型将输出划分为逻辑语义部分,从而改进结果。例如,通过对问题的要点进行自我反思(见上图),每个要点代表对问题不同部分的语义理解——一般描述、目标和规则、输入结构和输出结构。
LLM在生成模块化代码时做得更好
当要求 LLM生成单个冗长函数时,结果往往很差 – 代码通常包含错误或逻辑错误。
更糟糕的是,单个整体代码损害了执行迭代修复的能力——即使给出了错误消息,模型也难以查明和修复问题。
具有双重验证的软决策
LLM往往会在需要思考、推理并做出严格、重要决策的代码任务中遇到困难。
以针对问题生成附加测试的任务为例。很多时候,模型生成的一些测试是完全错误的。通过双重验证过程,作者添加了一个额外的步骤,在给定生成的输出的情况下,要求模型重新生成相同的输出,但在需要时进行更正。例如,将生成的 AI 测试作为输入,要求模型重新生成相同的测试,同时纠正错误的输出(如果存在)。我们发现,双重验证的这一步骤在鼓励模型批判性和推理性的同时,比直接问「是/否」问题更有效:「这个测试正确吗?」
推迟决策,尽量避免直接提问,并留出探索的空间
向模型提出有关复杂问题的直接问题时,我们总是会看到幻觉和错误答案。
采用逐步数据积累的流程,从简单的任务到困难的任务:从最简单的任务开始 – 对问题的自我反思,并对公共测试进行推理。开始生成额外的人工智能测试以及问题的可能解决方案。只有在获得模型对上述任务的答案后,我们才会开始实际的代码生成和运行修复迭代。
测试锚点
即使经过双重验证,一些人工智能生成的测试也会是错误的。
这使得迭代变得具有挑战性——当测试失败时,我们如何知道是因为代码错误,还是因为测试错误?当我们直接询问模型「谁错了」时,经常会看到幻觉,并可能最终得到错误修复的代码。为了解决这个问题,作者使用了「测试锚点」技术:– 首先迭代公共测试,我们知道这是正确的。完成后,将所有通过的测试设置为锚定测试。– 然后,一项一项地迭代人工智能生成的测试。如果测试通过,则将其添加到测试锚点列表中-如果测试失败,假设是因为代码不正确,并尝试修复代码。然而,要求固定代码也通过已经获得的所有测试锚点。因此,测试锚点将保护输出免受错误固定代码的影响。测试锚点的另一个优化是将人工智能生成的测试从易到难进行排序。这样,迭代过程就有更多机会在过程开始时获得锚点,这可以在以后迭代更复杂的人工智能测试时用作保护,因为错误测试输出的可能性更高。
结果
直接使用提示词 Vs AlphaCodium
将 AlphaCodium 结果与通过单个精心设计的直接提示获得的结果进行了比较。
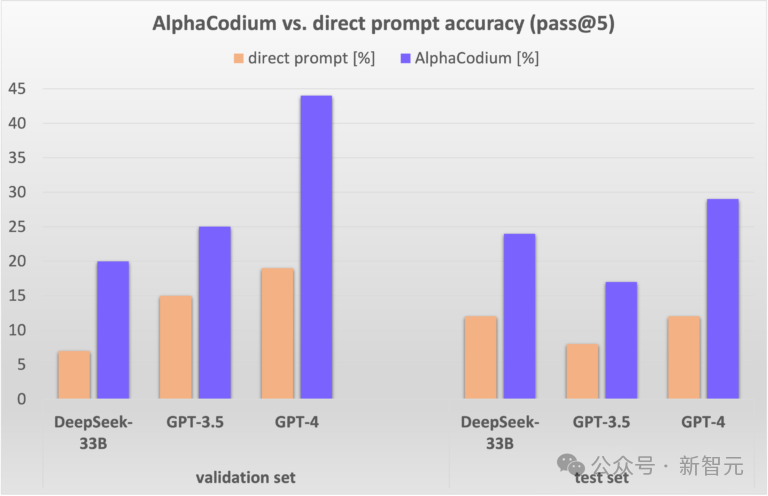
可以看出,AlphaCodium流程一致且显著提高了LLM在CodeContests问题上的性能。对于开源 (DeepSeek) 和闭源 (GPT) 模型以及验证集和测试集都是如此。参考资料:https://www.codium.ai/blog/alphacodium-state-of-the-art-code-generation-for-code-contests/














暂无评论内容