
GPGPU 的概念已经很火了,了解GPGPU的架构、功能对于我们优化AI 框架性能、国产自主研发AI芯片会有益处,所以我们在这对GPGPU 尝试做一个稍微全面的overview。也是对先前学习的总结。
理解GPU的基础
定位
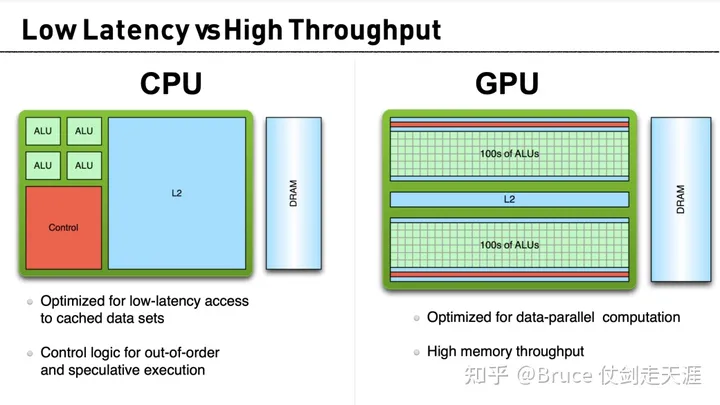
对CPU的评价
- Easy to program:compilers evolved right along with the hardware they run on. Software developers can ignore most of the complexity in modern CPUs; microarchitecture is almost invisible, and compiler magic hides the rest.
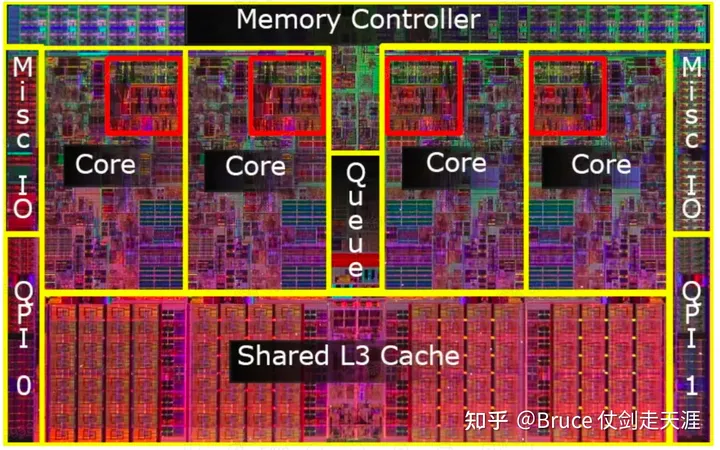
- optimized for single-threaded performance,not parallel execution。从板上设计看,cpu 大部分的面积用于指令decoder(包括寻址、取指、优化等等)与cache、分支预测上,整数计算和浮点计算写对面积却很少。不适合于HPC 大数据量运算的情况。
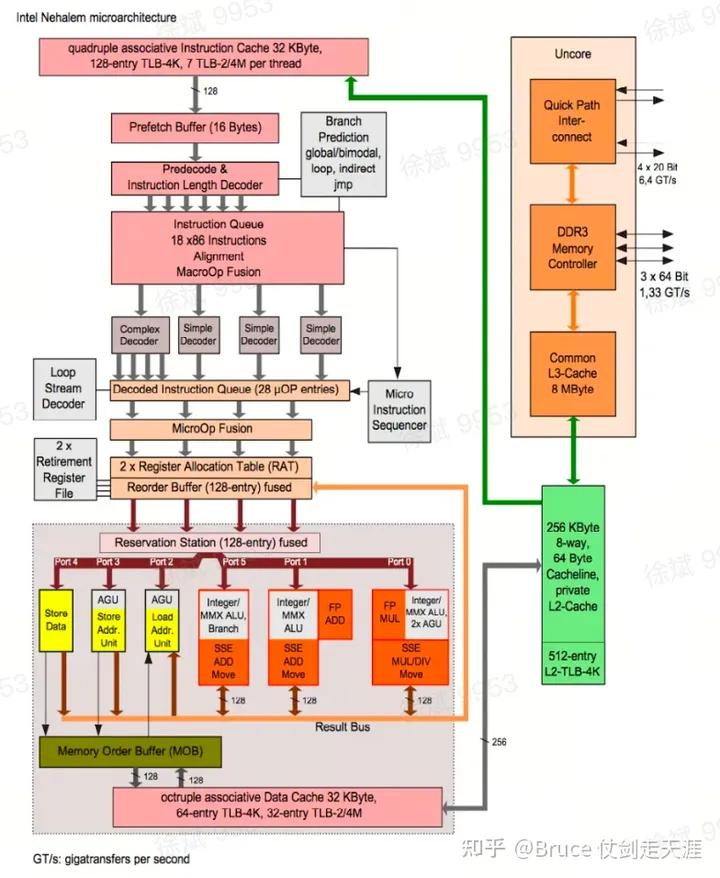
3. Speculation execution depends on high data locality、a mix of different operations and high percentage of conditional branch。
GPU
相对的,GPU(tesla 为例)的大部分面积用于计算(SM,SP面积占比大),更注重高带宽,不介意高延迟(GPU 指令目前的latency 都是相对大的,比对CPU)。但是cuda 之前,GPU的可编程性较差,并没有向软件程序员屏蔽硬件差异。
并行模型
SMT /SIMD/ SIMT
在并行模型中,常见有三种设计:
- SMT(Simultaneously multithreading),指多个thread 中并行运行不同的指令,Intel和AMD 在某些部分设计上采用了SMT
- SIMD(single instruction multiple data),指一条指令中的多个data可以并行执行。大部分CPU实现。
- SIMT(single instruction,multiple thread),指多个thread 运行同一指令,但各自处理的数据可以不同(一般每个线程的数据,尤其是寄存器是独立的)。比如GPU的实现
从灵活性而言:SMT> SIMT > SIMD, 从计算效率而言 SMID > SIMT > SMT,但是SIMD 本身能够执行的程序受限较大。SIMT 是灵活性与性能上的一个折中。
SIMD vs SIMT
GPU 的设计上与SIMD 相比有三处不同:
- 单指令,硬件上存在(需要)多套寄存器(SIMD 需要vector,要求并行处理的数据需要地址连续)
相比SIMD 的好处:编程友好,不需要程序员自己计算地址再执行指令
相比SIMD 的坏处:
- 可能造成不必要的寄存器/访存浪费(比如如果所有thread用的是同一个数据)
- 由于寄存器独立,无法根据实际数据的位宽进行访存和计算的优化,SIMT 永远需要计算num_thread* num_reg_width。(NVIDIA 不去支持的另一个原因是,当前最流行的是FP32,这种位宽优化意义不大)
2. 单指令,硬件存在(需要)多个访存单元
由于每个thread 有自己的存储,所以可以并行存取,相对一个访存入口竞争的设计,性能可以提高。
优势比较明显,劣势在于考虑GPU存储的多级性,thread 间独立并行访问,提高了设计难度。
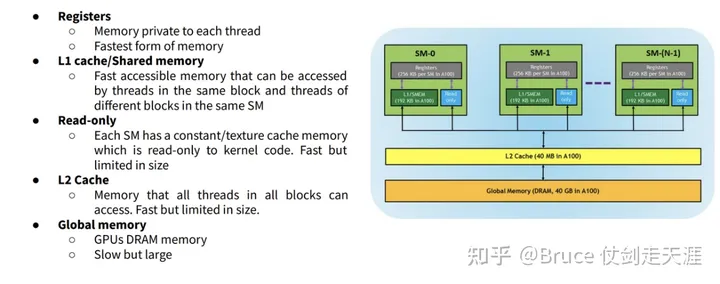
GPU的存储层次一般至少包括以下(离core 由近至远):share memory、L1、L2、DRAM。最近的share memory在SM 内,由SM 内core 共享(如regfile),最远的DRAM则在外部存储器中。
提高DRAM的访存效率的途径就是合并访问,从而尽可能减少向dram 访存的次数,由于thread的并行化,这一块请求合并的动态性要求更高。
Sharememory 由多个单独的bank 构成,share memory 需要处理多core随机访问造成的bank 冲突问题。如果一个bank 被两个地址访问,每个thread中其访存带宽会下降至1/2。
3. 由于SIMT 的实现,分支运算会带来一个问题。
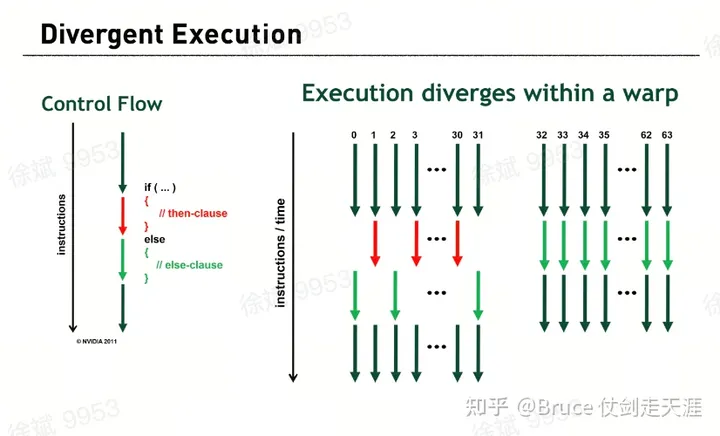
由于SIMT 的部分,执行的是同一指令,所以如果指令执行中发现有的thread 执行if 有的执行else,else的线程必须等待if的执行完,才能开始,而else thread执行时,if thread处于idle。
否则就是SMT了。
SMT vs SIMT
SMT 本身设计更加复杂,CPU 上SMT的实现,thread数量都在个位数(2,4),并不适用于高并行计算量的实现。
SIMT 的重要概念
| CUDA(NV GPU) | 名词解释 |
| Thread | 线程,单lane |
| Warp | 硬件调度的最小单元,SIMT单元,warp 内thread执行同一段指令 |
| Block | 软件运行的基本单元,内部可以进行同步 |
| Grid | 一段软件程序任务 |
| sm | 硬件的基本处理单元 |
| stream | GPU运行程序的一个组织单位,类似于CPU的进程。 |
Warp 内 的thread 必须是运行同一指令,每个block 需要一个sm 去运行,最后拆分成多个warp执行。每个grid 中存在许多block。
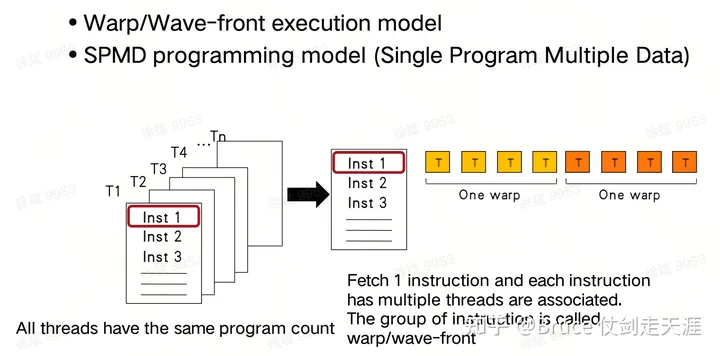
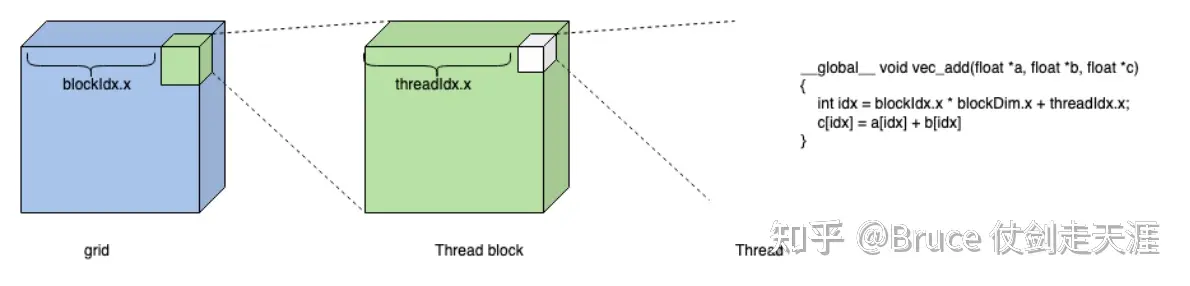
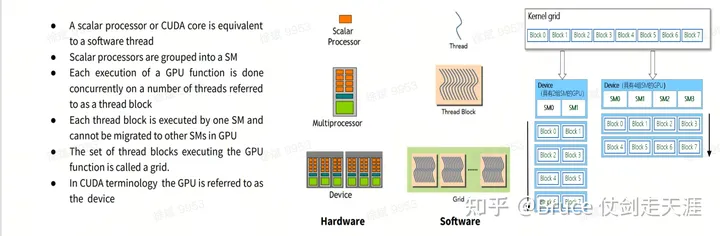
并行能力
指令执行
指令按序列顺序分发。如果某个指令不具备执行条件,则会挂起当前warp
指令具备执行条件必须满足两个条件:
- 流水线已准备好执行该指令,某些流水线步骤需要多个指令周期才能分发warp
- 所有参数已准备好。如果参数需要之前的指令计算的结果,那么只有当结果已计算出来才算准备好。
ILP 指令级并行
指令虽然是顺序分发的,但是还是有可能并行执行
- 相互依赖的大指令之间的那些互相独立的小指令可以被并行执行
- ILP是否成立取决于编译器编译出的指令序列

图中两个FMUL指令是并行的(ILP),因为他们是相互独立的,但是它们所依赖的指令(FFMA)以及依赖它们的指令(ST.E)则不能并行。
Warp 切换
如果当前执行的warp的指令不具备执行条件,则会挂起warp。例如挂起了N个周期,那么会有N个其他的waprs的具备执行条件的指令被执行。也就是说同一个warp硬件上会来回切换执行不同的warp,已充分的利用硬件。 切换warp没有性能负担,因为寄存器,共享内存这些状态是划分给这些warp的,没有存储/恢复操作发生。
Warp 切换的几种算法如下:
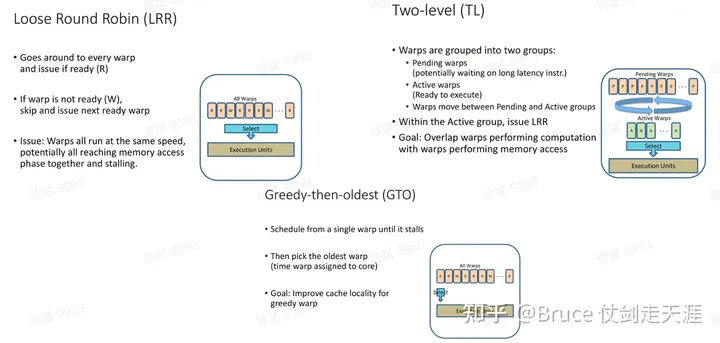
存储模型
内存连贯性与缓存一致性
内存连贯性是说软件运行时,软件的指令顺序执行后,结果上应该是连贯的。
由于存储的多级架构,缓存的引入必不可少,于是为了保证内存访问执行后的结果符合预期,就出现了缓存一致性,可以说,缓存一致性是为内存连贯性服务的。内存连贯性与缓存一致性不同,内存连贯性可以将缓存一致性作为一种可用的黑盒特性。
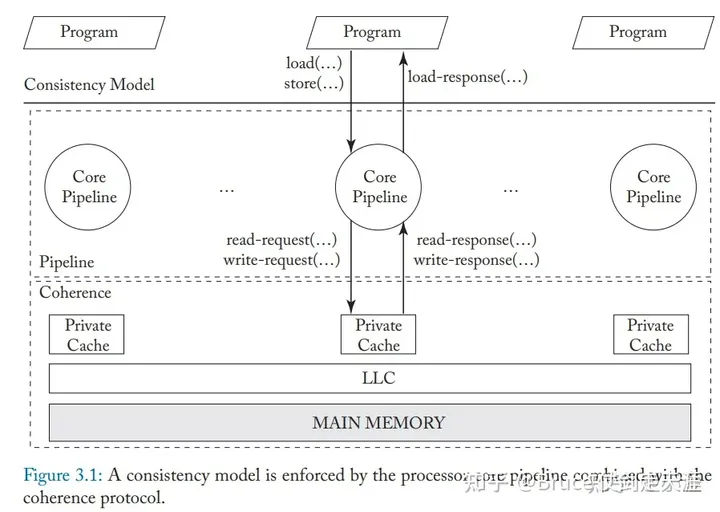
之所以了解这个概念,源自于GPU和CPU采用了不同的访存模型。也就涉及到处理器设计的内存访问排序和乱序执行问题,不过内存连贯性只涉及访存指令的顺序(处理load-load,load-store,store-store,store-load 乱序的办法),但不限制计算指令。
访存模型一共包括四种:
- SC(Sequencial Consistency)
处理器上硬件指令执行的顺序与软件程序顺序一致,也就说完全没有乱序过程。
2. TSO(total stored ordering)
TSO允许STORE — LOAD内存重排序,也就是load操作可以在store前发生,比如X86就是这种模型。x86没有使用推测技术,访存指令重排只支持STORE-LOAD重排序,不支持其它访存重排序,但是其它非访存指令还是可以重排的。
3. PSO (partial stored ordering)
在TSO的基础上继续允许store-store乱序,即同时支持store-load 乱序和store-store 乱序。
4. RC (relaxed Memory consistency)
支持以上四种重排序(load-load,store-store,store-load,load-store),名副其实宽松连贯性。RC在可编程性、移植性、精确度上逊于TSO,但是性能上更优。GPU 采用的就是RC,不过GPU 设计时提出了许多scope的概念,以此乱序的范围也是根据scope 不同而定,提高了一部分对乱序的控制。
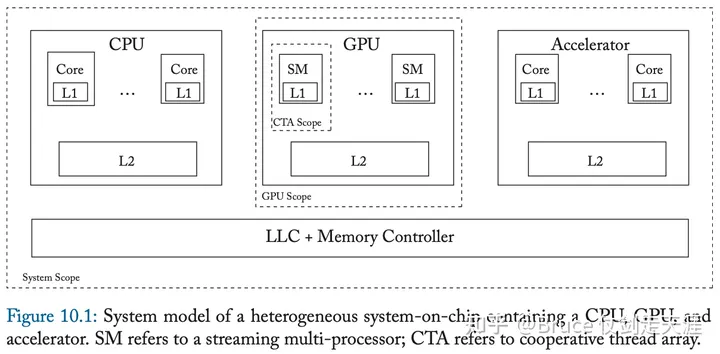
此外,这里列一张图,大家可以了解内存连贯性在不同处理器上的支持情况。
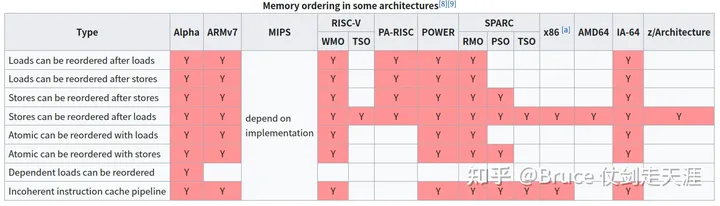
存储系统架构
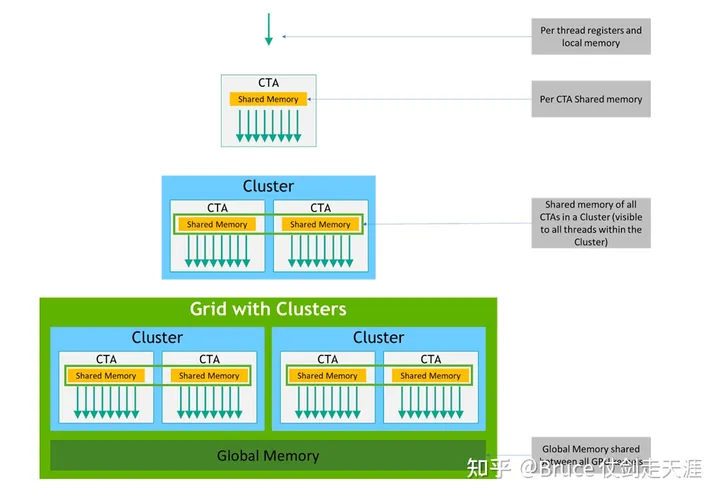
总体而言,GPGPU的存储布局如下。
Regfile
Regfile 是一种sharememory,通常划分为多个Bank,4个Register Bank组成的R寄存器文件结构如下,每个Register Bank又可以包含两个RAM。


GPU中,每个执行核中的寄存器的容量和这个核支持的最大线程数息息相关。
假设每个执行核最多支持A个Warp,每个Warp包含B个线程,每个线程可用的寄存器为:通用寄存器C个、特殊寄存器D个,每个寄存器为E个字节,则这个执行核的寄存器文件的大小为: A×B×(C+D)×E 。
将Register File拆分成多个Register Bank是为了提高寄存器的访问效率。因为每个Register Bank都有独立的访问端口,这样多个Bank就可以并行访问。
shared memory
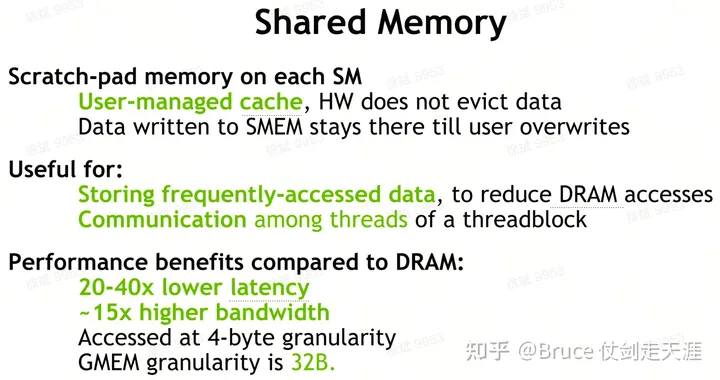
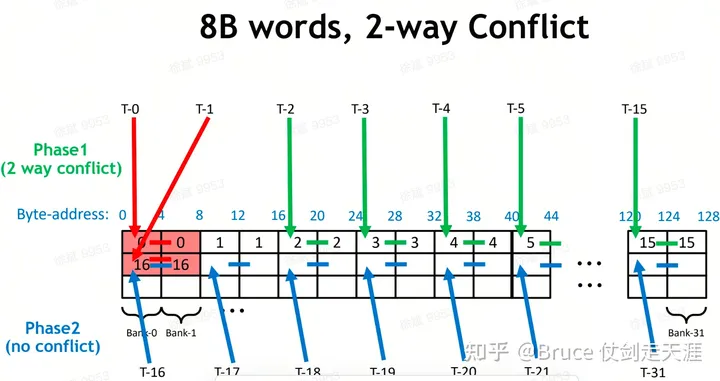
Sharemem 也有类似的bankconflict 问题。

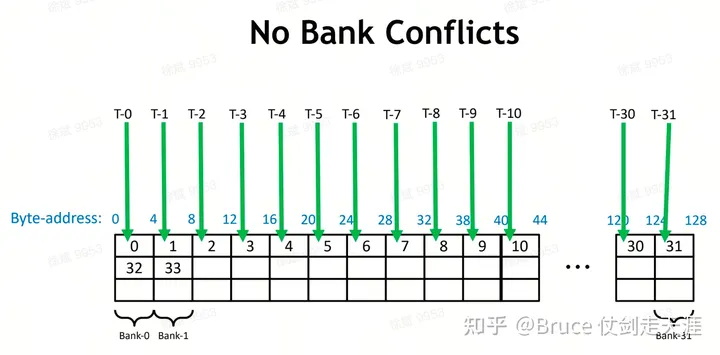
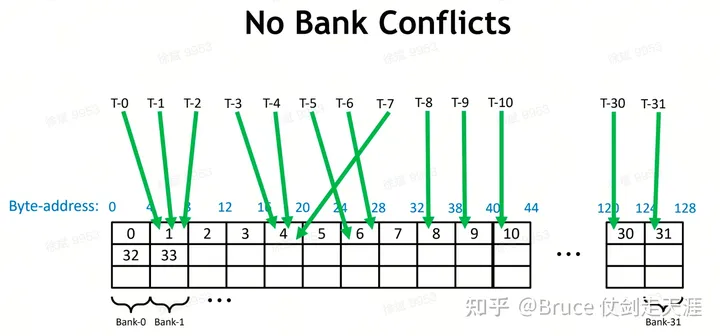
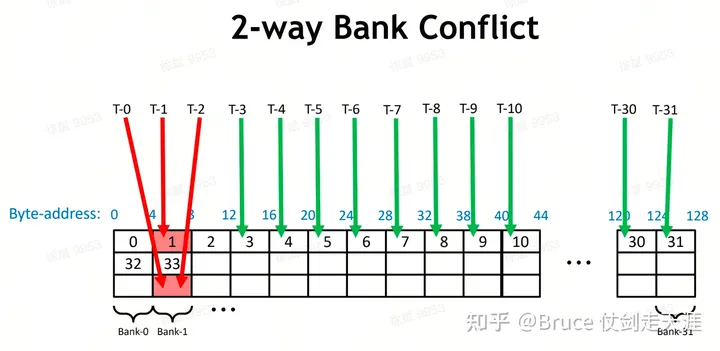
解决 banconflicts的方法:对同一个bank的访存分散在不同warp/phase中。

L1 与 L2 cache
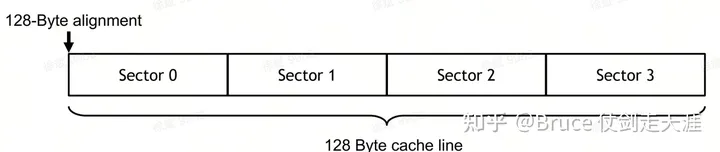
L1/L2 属于cache,cache 与dram 打交道,是通过cacheline flush/write操作进行的,目前GPU 内一个cacheline 128 byte,分为四个sector,一个sector 32byte,cacheline 是 cache 管理的最小单元,sector 是数据读写的最小单元。
为什么需要L1和L2呢?明明有share memory可以处理缓存


同时需要注意warp 访问L1/L2的pattern。

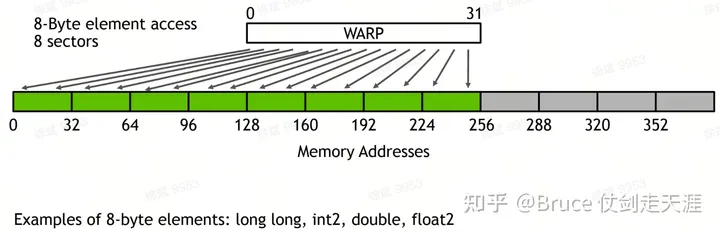
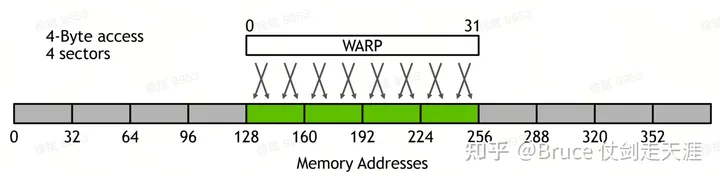
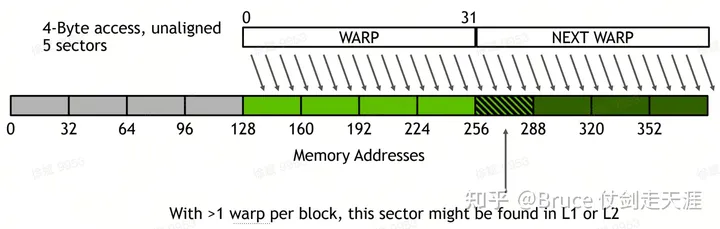
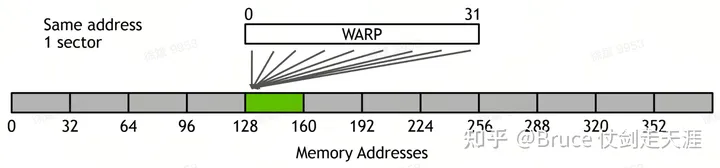
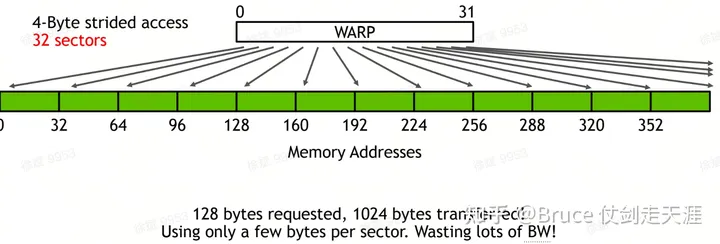
检查自己的access paterrn 非常重要,warp 访问同时不同sector的数量,决定了warp 访存的带宽,sector 越多潜在并行性越好,但也越容易和其它warp 产生访存冲突,造成性能下降。
Tesla – GPGPU 之前
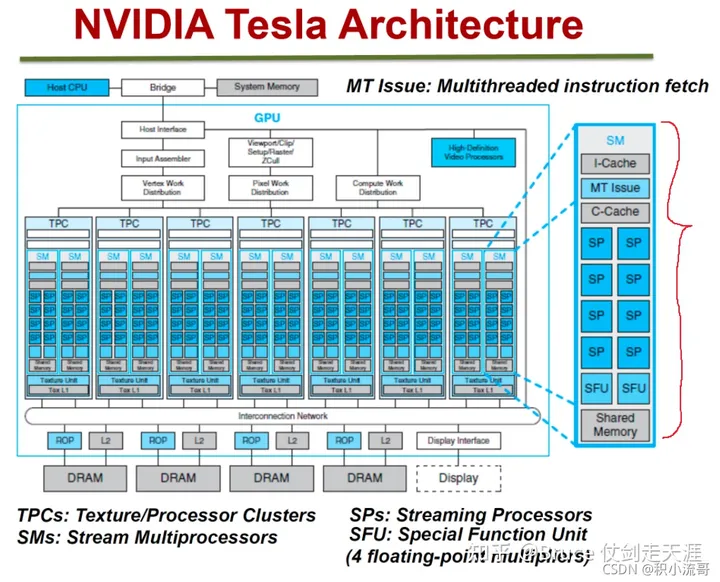
Tesla 架构
Tesla架构主要包含G80 和GT200 两个版本,是NVIDIA第一代“统一着色与计算架构”(unified shader and compute architecture),也是GPGPU 之前最后一个架构,其架构图如下:
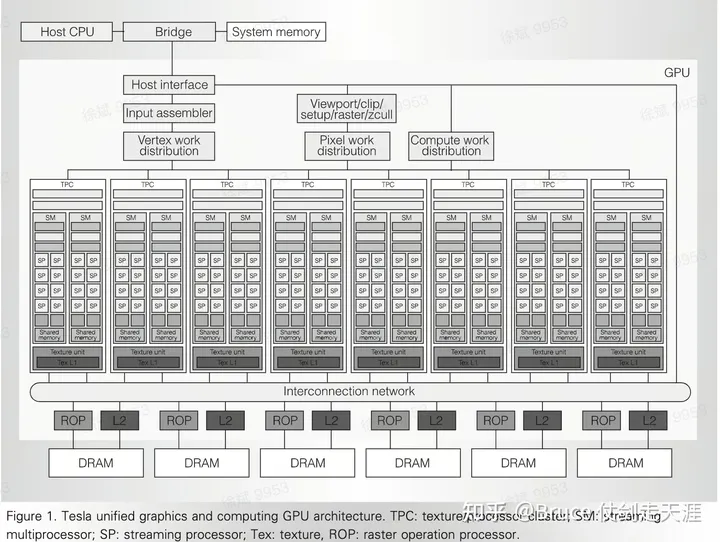
主机(host cpu)和系统内存(system memory)通过内部BUS总线+接口(host interface,一般是PCI/PCIE插槽)与GPU交互。整个架构从上到下大至分为三个区域:
- 调度与分发区域:包括顶点任务分发通道:Input assembler + Vertex work distribution; 像素任务分发通道:Viewport/clip/setup/raster/zcull + Pixel work distribution; 计算任务分发通道 Compute work distribution。这些通道负责具体的计算任务的准备以及匹配对应的计算单元来下发相应的任务。
- 计算区域:主要有阵列式的处理族TPC( texture/processor cluster)组成,TPC负责完成具体的运算工作,TPC的数量可根据需求改变,。
- 存储与处理区域:主要完成存储和一些预处,包括:光栅操作器ROP( raster operation processor)、缓存L2 cache、全局内存DRAM。
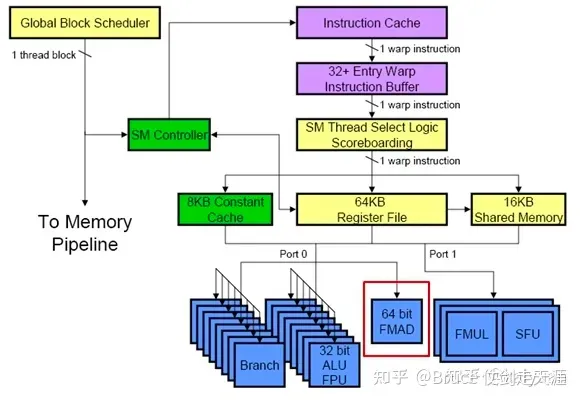
可以关注这个时候的SM 是 TPC 内部的模块,其逻辑如下:
对Tesla的认识
大家可以看到几个特点:
- 计算单元大量占据板上面积,计算资源侧重明显
- 图形场景处理专用,texture,rop,pixel,vetex 都是计算机图形处理领域的模块
- 已经存在最初的SM 架构和warp scheduler以及global scheduler,该架构为GPGPU 核心模块,是计算并行能力的保证
- 存储层级还比较少,没有明显的LLC、L2和L1的设计
为何需要GPGPU?
大数据量计算需求和场景逐渐增多。显然只专注于图形、游戏、渲染领域是固步自封的做法,为此需要布局通用GPU的赛道。而通用GPU 依赖什么呢?
- 硬件设计的通用性,从以前图形渲染场景和设计中跳脱出来,实现更通用的适合大数据高性能计算的并行架构
- 可编程性,使得开发者可以屏蔽细节,最大限度最小代价地使用好硬件能力,于是出现了CUDA。
GPGPU 架构图示例-A100
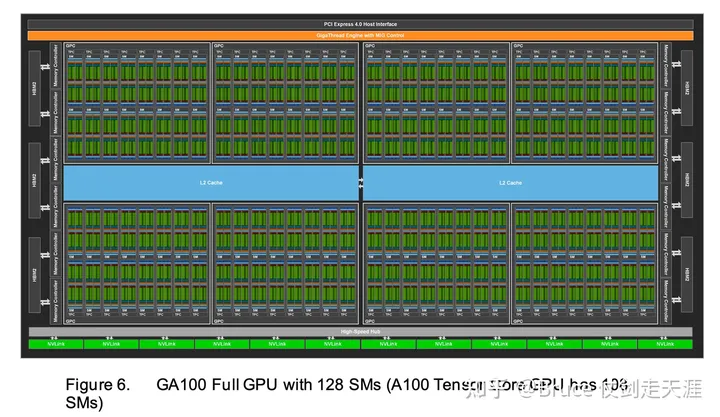
我们之后会大力说明硬件架构的演进过程,这里先说一下GPGPU 的另二功臣-编译器NVCC和通用计算库CUDA。
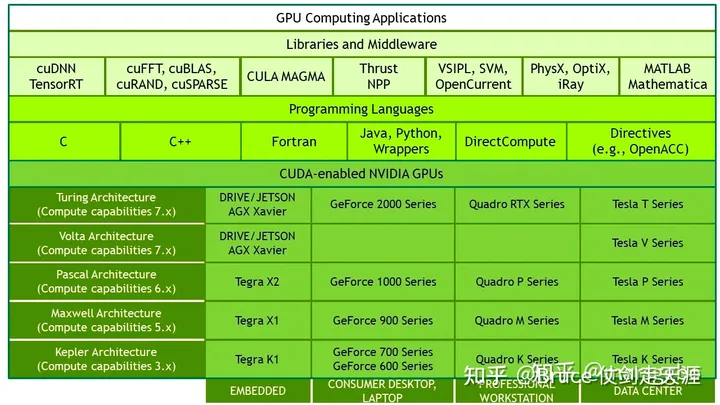
CUDA 全家桶
Cuda 全名compute unified device architecure。由英伟达NVIDIA所推出的一种软硬件集成技术,透过这个技术,用户可利用NVIDIA的GPU进行图像处理之外的运算,亦是首次可以利用GPU作为C-编译器的开发环境。实现了GPU 用于通用计算的能力,目前CUDA 已经支持并开发出了多种计算库,比如cudnn、cublas,cufft等等,且支持多种语言,包括实验室常用的matlab。
编译 – NVCC
nvcc是CUDA的编译器,可以从CUDA Toolkit的/bin目录中获取,类似于gcc就是c语言的编译器。由于程序是要经过编译器编程成可执行的二进制文件,而cuda程序有两种代码,一种是运行在cpu上的host代码,一种是运行在gpu上的device代码,所以nvcc编译器要保证两部分代码能够编译成二进制文件在不同的机器上执行。
这里特别需要注意两个宏的差别:
- __global__ void KernelFunc() 只能从主机端调用,在设备上执行
- __device__ float DeviceFunc() 设备端调用 设备端执行
- __host__ float HostFunc() 主机调用 主机执行
__global__与__device__,这两个宏所标记的函数都可以在device 上运行。但是存在差别,__global__ 可以由CPU 侧发起,但是__device__ 不允许cpu 侧发起,必须完全在gpu上执行。
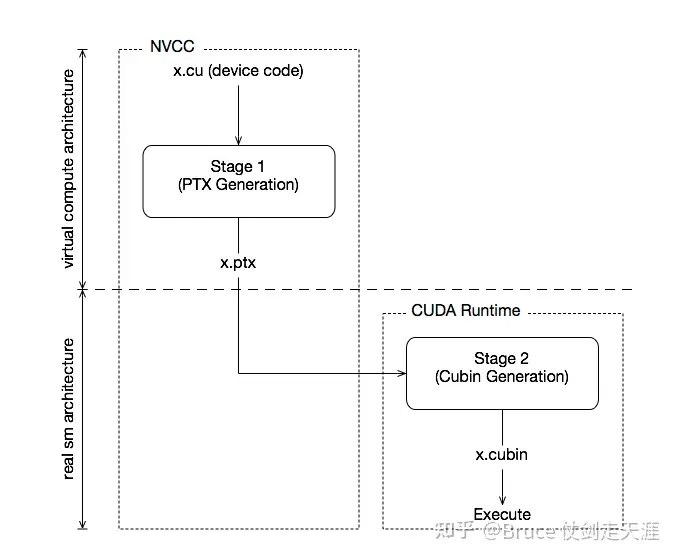
接下来是nvcc 链接host code 和 device code的流程图。凭借nvcc,我们可以将device code代码和host code放到一个git仓,配置后统一编译,即可分别生成两个终端上执行的代码。
Host 上的编译链接过程
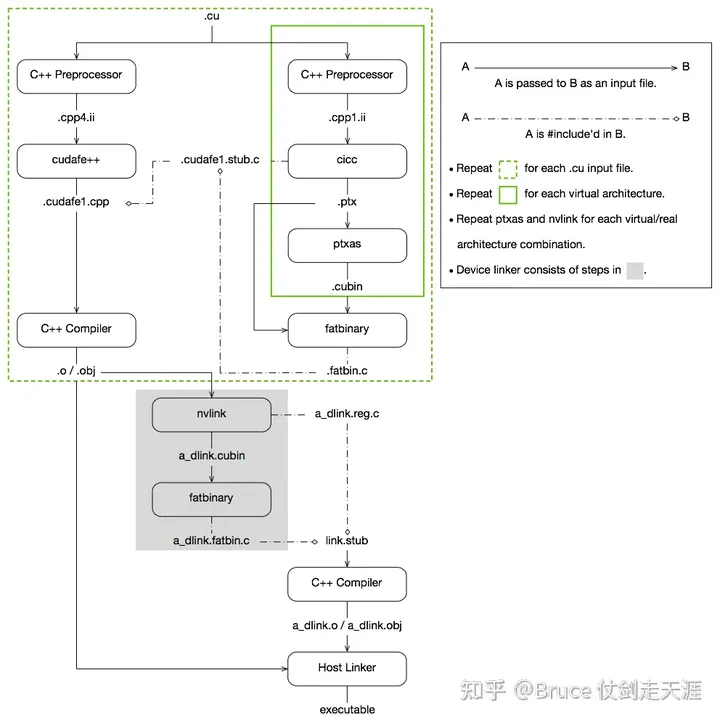
Device code 常规编译链接过程(AOT)
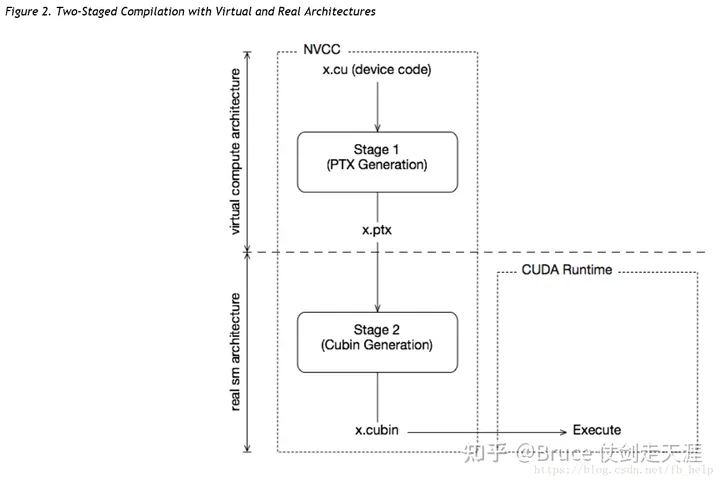
Device code JIT 模式编译链接过程
历代特性添加
Fermi
Fermi架构于2010年4月发布,采用40nm/28nm(部分移动产品采用28nm)工艺技术生产。新特性如下:
- CUDA core的精度运算能力提升,支持FMA(以前叫SP,Fermi 开始改叫cuda core);
- 支持同一个上下文内的算子并行(kernel 并行);
- 增加ECC功能;
- 指令分发采用双warp调度;
- GigaThread能力增强,上下文切换速度变快;(从fermi 开始叫gigathread engine,tesla 叫global thread scheduler)
- 内存结构的完善
Kepler
Kepler 架构于2012年4月发布,采用TSMC的28nm工艺技术生产,芯片代码“GKXXX”主要是GK110和GK210,这代架构的主要亮点:
- 动态并行(Dynamic Parallelism): 支持在GPU内创建kernel;增加网格管理单元(Grid Mangement Unit)
- 超级队列(Hyper-Q): 让不同进程的CUDA streams 拥有更多的物理队列,增加并发度;
- warp内的数据操作(Warp Shuffle Instructions): 在warp内的数据能够直接在寄存器进行交换,不需通过shared memory;
- GPU超频( Boost)
- 图形相关视频的加解码器(NVDEC/NVENC)、无绑定的纹理处理(Bindless texture)
- 四并行warp(Quad Warp)
- 多机GPU之间的直接访问(GPUDirectrdma)。
Maxwell
Maxwell架构在2014年发布,基于TSMC的28nm工艺,由于工艺与上一代kepler相同,而性能又要大幅提升,所以Maxwell的芯片基板面积会增加不少,以GM107为例,其大小为148mm^2,对比GK107大小118mm^2,增加了25%的面积。 maxwell发行了两代芯片GM10X和GM20X,相比kepler,其主要特点:
- 对SM进行了优化,提出了SMM,效率更高,SM的指令执行与下发进行了分块;
- 改进了shared memory;
- 同计算量下功耗更低;
Pascal
Pascal架构在2016年4月发布,采用TSMC的16nm FinFET工艺技术生产,芯片代码“GPXXX”如GP100,这代架构的主要亮点:
- 推出了第一代NVLink(NCCL 随之推出);
- 首款采用HBM2内存的GPU架构;
- 统一内存UVM进行了地址和操作的优化;
Volta
- 第一代Tensor core
- Warp 内thread 可独立调度
- Ecc 加强
- Page fault 处理优化
- 优化MPS
- Cooperative Groups
- Nvlink 第二代(如 Nvlink 支持 ATS)
Turing
Turing 发布于2018年的温哥华 siggraph 大会。
- 新一代SM 架构
- Nvlink 第二代(如 Nvlink 支持 SLI)
- 第二代tensor core(如Tensor core支持 DLSS)
- 图形相关能力:比如实时光线追踪的加速、多速率阴影、文本空间阴影、多视图渲染
- 对深度学习图形处理的支持
- 对深度学习推理的支持
- 支持USB-C 和 Virtuallink(VR 相关接口)
Amphere
2020年发布
- 第三代nvlink switch
- 第三代tensor core
- MIG
- 支持mellanox和nvidia magtumn IO
- 支持sparse tensor core
- Pcie gen4 with SRIOV
- 访存优化
- 侧重最大化支持deep learning
Hopper
2022年发布
- Pcie gen5
- 支持超算数据中心(DXG)
- DPX 指令支持动态编程
- Thread block cluster
- Distributed shared memory
- 异步执行能力增强(Tensor memory accelarator,Asynchronous Transaction Barrier)
- 内存子系统ras 增强(memory row remapping)
- 第二代安全MIG
- 支持transformer engine
- 四代nvlink与三代nvswitch,sharp
- 可信计算支持
历代规格比对
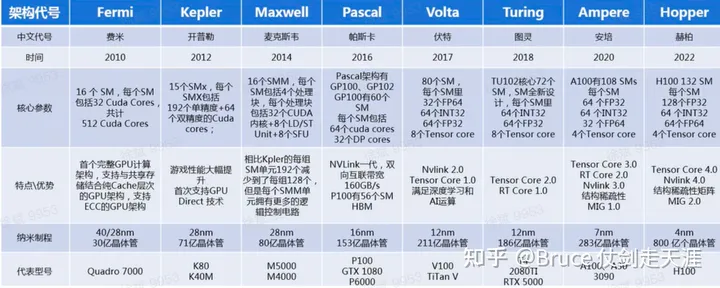
规格变化的总特点:
- 纳米制程变小
- 并行能力提高(SM 内 Core 数增加,SM 总数增加,SM 时钟频率变高)
- 存储带宽变大(从ddr4到HBM3,存储时钟频率变高)
- 存储总量变大(dram,regfile,cache 都满足该趋势)
- 功能向AI 倾斜(从tensor core到sparse tensor core,到transformer engine)
- 向大规模集群计算演进(nvlink/nvswitch 的代代演进)
Compute capability
设备的Compute Capability由版本号表示,有时也称其“SM版本”。该版本号标识GPU硬件支持的特性,并由应用程序在运行时使用,以确定当前GPU上可用的硬件特性和指令。
Compute Capability包括一个主要版本号X和一个次要版本号Y,用X.Y表示
主版本号相同的设备具有相同的核心架构。设备的主要修订号是8,为NVIDIA Ampere GPU的体系结构的基础上,7基于Volta设备架构,6设备基于Pascal架构,5设备基于Maxwell架构,3基于Kepler架构的设备,2设备基于Fermi架构,1是基于Tesla架构的设备,最新的Hopper 则是9。
次要修订号对应于对核心架构的增量改进,可能包括新特性。
Turing是计算能力7.5的设备架构,是基于Volta架构的增量更新。














暂无评论内容