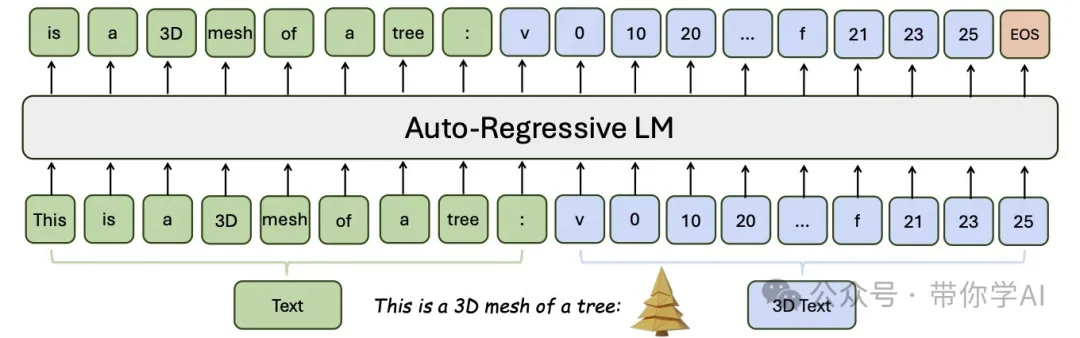
目前常见的有文生文、文生3D模型,但目前还没有问答式混合模型。清华和英伟达这项研究探索了如何让以文本预训练的大型语言模型(LLM)具备生成3D网格的能力,实现“文本+3D”一体化的模型。这么做有两个主要好处:可以利用LLM从3D教程等文本来源中学到的空间知识;支持对话式的3D生成和网格理解。这是首次证明LLM通过微调可以掌握复杂的空间知识,用“文本格式”完成3D网格生成,真正实现了文本和3D的融合。但一个关键问题是:如何把3D网格的数据转成LLM能理解的“离散的词”?为了解决这个问题,提出了 LLaMA-Mesh,把3D网格的顶点坐标和面定义直接表示为普通文本。这种方法不用修改LLM的词汇表,就能把3D网格数据轻松“喂”给模型。
技术原理—LLAMA-MESH 将文字和3D模型统一成一种格式,把3D模型中顶点坐标和面片定义的数值转化成普通文字表示。模型通过同时学习文字和3D数据,直接进行端到端训练。因此,我们只需要一个统一的模型,就能同时生成文字和3D模型!
和之前的自动回归3D生成方法类似,LLAMA-MESH模型在训练中学会了模型的结构布局,因此生成的拓扑看起来更像是专业艺术家的作品。
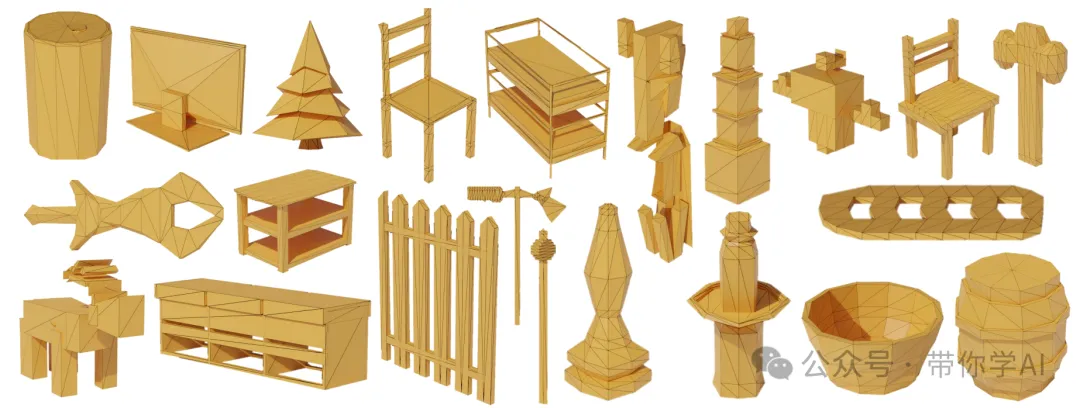
为了测试生成的3D模型有多丰富多样,用相同的文字描述多次生成模型,并观察结果的变化。模型生成了许多独特的3D模型,它们都符合描述要求。这说明LLAMA-MESH方法可以产出多样化且富有创意的结果。这种多样性对于需要多个设计选项或变体的场景来说尤为重要。
采用了一种简单的方式来表示3D网格:把网格的顶点坐标和面片信息用纯文本形式保存。这样可以直接和大型语言模型(LLMs)对接,不需要额外增加模型的词汇量。
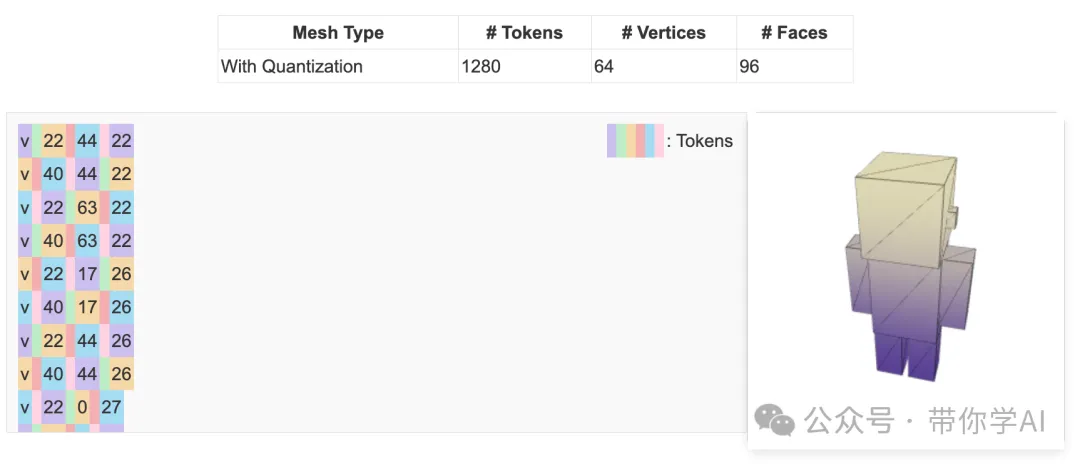
左边是一个OBJ文件的片段,它用纯文本记录了顶点(v)和面片(f)的定义;右边是根据这个OBJ文件渲染出的3D模型。通俗来说,就是把3D模型的构造信息写成类似代码的文本,然后用这个文本生成3D形状。














暂无评论内容