DeepSpeed:所有人都能用的超大规模模型训练工具
译者:zhuzilin
校对者:samyu2000、luochen1992、lsvih
我们于今年 2 月份发布了 DeepSpeed。这是一个开源深度学习训练优化库,其中包含的一个新的显存优化技术—— ZeRO(零冗余优化器),通过扩大规模,提升速度,控制成本,提升可用性,极大地推进了大模型训练能力。DeepSpeed 已经帮助研究人员开发了图灵自然语言生成模型( Turing-NLG),其在发表时为世界上最大的语言模型(拥有 170 亿参数),并有着最佳的精度。我们在 5 月份发布了 ZeRO-2——支持有着 2000 亿参数的模型训练,与最新技术相比,训练速度可达 10 倍——以及一系列计算、IO 和收敛优化功能,从而助力最快速的 BERT 训练。自那时起,我们持续高速地进行创新,不断突破深度学习模型训练的速度和规模的边界。
今天,我们非常开心地跟大家分享一些新的进展,这些进展不仅会推动深度学习训练走向极致,同时也让这份技术的使用范围更加广泛——上至数据科学家们在超算上训练,下至在低端集群甚至仅仅一张 GPU 上训练。具体来说,DeepSpeed 加入了 4 项系统性新技术来进一步拓展我们的 AI at Scale 倡议。它们也推动了微软的AI产品与平台的创新。这些技术提供了极为高效的计算、显存和通信的利用效率,并助力我们训练有着十亿至万亿量级参数的模型。这些技术也支持超长输入序列,并且无论在单卡GPU、千卡GPU的高端集群上,还是在慢速以太网的低端集群上均可以使用。
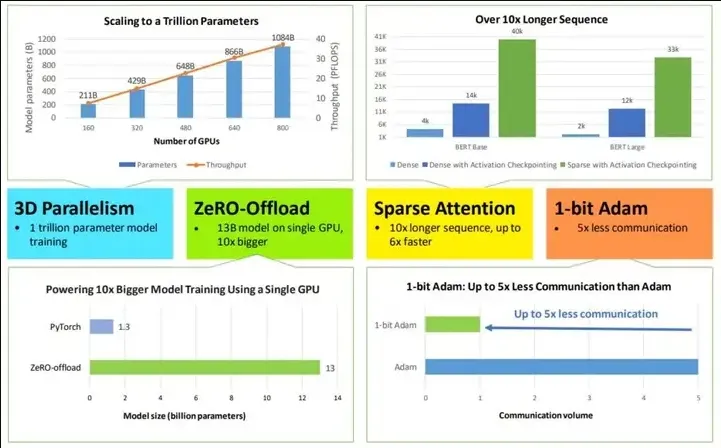
- 用 3D 并行化实现万亿参数模型训练: DeepSpeed 实现了三种并行方法的灵活组合:ZeRO 支持的数据并行,流水线并行和张量切片模型并行。3D 并行性适应了不同工作负载的需求,以支持具有万亿参数的超大型模型,同时实现了近乎完美的显存扩展性和吞吐量扩展效率。此外,其提高的通信效率使用户可以在网络带宽有限的常规群集上以 2-7 倍的速度训练有数十亿参数的模型。
- ZeRO-Offload 使 GPU 单卡能够训练 10 倍大的模型: 为了同时利用 CPU 和 GPU 内存来训练大型模型,我们扩展了 ZeRO-2。我们的用户在使用带有单张英伟达 V100 GPU 的机器时,可以在不耗尽显存的情况下运行多达 130 亿个参数的模型,模型规模扩展至现有方法的10倍,并保持有竞争力的吞吐量。此功能使数十亿参数的模型训练更加大众化,,并为许多深度学习从业人员打开了一扇探索更大更好的模型的窗户。
- 通过 DeepSpeed Sparse Attention 用6倍速度执行10倍长的序列: DeepSpeed提供了稀疏 attention kernel ——一种工具性技术,可支持长序列的模型输入,包括文本输入,图像输入和语音输入。与经典的稠密 Transformer 相比,它支持的输入序列长一个数量级,并在保持相当的精度下获得最高 6 倍的执行速度提升。它还比最新的稀疏实现快 1.5–3 倍。此外,我们的稀疏 kernel 灵活支持稀疏格式,使用户能够通过自定义稀疏结构进行创新。
- 1 比特 Adam 减少 5 倍通信量: Adam 是一个在大规模深度学习模型训练场景下的有效的(也许是最广为应用的)优化器。然而,它与通信效率优化算法往往不兼容。因此,在跨设备进行分布式扩展时,通信开销可能成为瓶颈。我们推出了一种 1 比特 Adam 新算法,以及其高效实现。该算法最多可减少 5 倍通信量,同时实现了与Adam相似的收敛率。在通信受限的场景下,我们观察到分布式训练速度提升了 3.5 倍,这使得该算法可以扩展到不同类型的 GPU 群集和网络环境。
a screenshot of a cell phone
这篇博文将深入探究这 4 项技术。我们已经将这些激动人心的优化技术公布在了开源项目 DeepSpeed中。
开源项目 DeepSpeed
https://github.com/microsoft/DeepSpeed
3D 并行:扩展至万亿参数模型
随着现代 GPU 群集上计算量的快速增长,训练具有惊人的功能的、强大的万亿参数模型不再是遥不可及的,可能在不久的将来就能实现。DeepSpeed 结合了三项强大的技术,可以训练数万亿规模的模型并扩展到数千个 GPU:数据并行训练,模型并行训练和流水线并行训练。这三者的共生让深度学习训练的规模远远超出了单独使用每种策略可以企及的。3D 并行同时解决了训练万亿参数模型的两个基本挑战:显存效率和计算效率。因此,DeepSpeed 可以扩展至在显存中放下最巨大的模型,而不会牺牲速度。
了解训练巨大模型的显存和计算效率的挑战
显存效率:训练万亿参数模型所需的显存远远超出了单张 GPU 的显存大小的。在使用 Adam 优化器进行混合精度训练时,存储模型状态量(参数、梯度和优化器状态量)就需要约 16TB 的显存。作为比较,最先进的英伟达 A100 GPU 只有 40 GB 的显存。仅仅为了存储模型状态,就需要 400 张这样的 GPU。
激活函数额外消耗的显存随 batch 大小而增加。batch 设置为1的情况下,训练万亿参数模型就会产生超过 1 TB 的激活函数用的显存(后文称为激活显存)。用 checkpoint 处理激活显存,用计算来换显存,可以将该显存减少到大约20 GB,但是对于训练而言仍然过高了。
必须在多个 GPU 设备之间有效地划分模型状态量和激活显存,才能让这种大模型在不耗尽显存的情况下开始训练。
计算效率:经估算端到端训练一个万亿参数的模型大约需要 5000 Zflops(即 5 后面带有 24 个零;这个估算结果基于 OpenAI 的研究 law of scaling)。这意味着训练这样一个模型需要 4000 张 A100 以 50% 的计算效率运行大约 100 天。
尽管大型超级计算 GPU 集群可以拥有超过 4000 个 GPU,但是由于 batch 大小的限制,要在这种规模上实现高计算效率仍然是一项挑战。计算效率随着计算时间对通信时间的比例的增加而增加。该比例与 batch 大小成正比。但是,训练模型的 batch 大小有一个上限——超过这个上限收敛情况会明显变差。
实际上最大的模型之一,GPT-3 的训练 batch 大小约 1500。如果使用大约 4000 张 GPU, 即使我们可以自由设置 batch 大小为 4000,每张卡上的 batch 大小也只有 1,这将影响扩展性。
理解数据并行、模型并行和流水线并行之间的权衡
数据并行是深度学习中的一种普遍使用的技术。在该技术中,每批输入的训练数据都在数据并行的 worker 之间平分。反向传播后需要通信并规约梯度,以保证优化器在各个 worker 上进行相同的更新。数据并行性具有几个明显的优势,包括计算效率高和实现起来工作量小。但是,数据并行的 batch 大小随 worker 数量提高,而我们往往无法在不影响收敛性的情况下一直增加 batch 大小。
显存效率:数据并行会在所有 worker 之间进行模型和优化器的复制,因此显存效率不高。DeepSpeed 开发了 ZeRO ,它是一系列用于提高数据并行的显存效率的优化器。 这项工作依赖于 ZeRO 的 1 阶段,该阶段在 worker 之间划分优化器状态量以减少冗余。
计算效率:随着我们提高并行度,每个 worker 执行的计算量是恒定的。数据并行可以在小规模上实现近乎线性扩展。但是,在 worker 之间规约梯度的通信开销跟模型大小成正相关,所以当模型很大或通信带宽很低时,计算效率会受限。。梯度累积是一种用来均摊通信成本的一种常用策略。它会进一步增加batch大小,在本地使用 micro-batch 多次进行正向和反向传播积累梯度后,再进行梯度规约和优化器更新。
模型并行是包含范围很广的一类技术。它会在多个 worker 之间划分模型的各个层。就其本质而言,模型并行性的计算和通信因模型结构而异,因此在实现上有很大的工作量。DeepSpeed 借用了英伟达的 Megatron-LM 来为基于 Transformer 的语言模型提供大规模模型并行功能。模型并行会根据 worker 数量成比例地减少显存使用量,也是这三种并行度中显存效率最高的。但是其代价是计算效率最低。
- 显存效率:模型并行会根据 worker 数量成比例地减少显存使用量。至关重要的是,这是减少单个网络层的激活显存的唯一方法。DeepSpeed 通过在模型并行 worker 之间划分激活显存来进一步提高显存效率。
- 计算效率:由于每次前向和反向传播中都需要额外通信激活值,模型并行的计算效率很低。模型并行需要高通信带宽,并且不能很好地扩展到通信带宽受限的节点。此外,每个模型并行worker 都会减少每个通信阶段之间执行的计算量,从而影响计算效率。模型并行性通常与数据并行性结合使用,以在内存和计算效率之间进行权衡。
流水线并行训练引擎也被包含在了这次发布的DeepSpeed中!流水线并行将模型的各层划分为可以并行处理的阶段。当一个阶段完成一个 micro-batch 的正向传递时,激活内存将被通信至流水线的下一个阶段。类似地,当下一阶段完成反向传播时,将通过管道反向通信梯度。必须同时计算多个 micro-batch 以确保流水线的各个阶段能并行计算。目前已经开发出了几种用于权衡内存和计算效率以及收敛行为的方法,例如 PipeDream。DeepSpeed 采用的方法是通过梯度累积来实现并行,并保持与传统数据并行和模型并行训练在相同的总 batch 大小下收敛情况相同。
- 显存效率:流水线并行减少的显存与流水线的阶段数成正比,使模型的大小可以随 worker 的数量线性扩展。但是,流水线并行不会减少每一层的激活函数的显存占用量。此外,每个 worker 必须存储同时运行的各个 micro-batch 的激活值。这导致流水线第一阶段的激活内存与单个 mirco batch 的总激活内存大致相同。一个万亿参数模型将需要为一个 micro batch 提供大约 19 GB 的显存的激活内存,这几乎占到新推出的英伟达 A100 GPU 总显存的一半。
- 计算效率:流水线并行具有最低的通信量,因为它的通信量只和在各阶段边界的各层的激活值大小成正比。但是,它不能无限扩展。像模型并行一样,增加流水线大小会减少每个流水线阶段的计算量,这会降低计算与通信的比率。如果要实现好的计算效率,流水线并行还要求其每个阶段的计算负载完美的均衡。
此外,流水线并行性会在每个 batch 的开始和结束时因为需要重新填充或排空流水线而产生 bubble overhead。使用流水线阶段数的 4 倍或 8 倍的梯度累积步骤(以及 batch 大小)进行训练,相较于只有一个流水线阶段分别达到了 81% 和 90% 的扩展性。
通过3D并行同时实现高内存效率和高计算效率
数据,模型和流水线并行在提高内存和计算效率方面均起到特定的作用。图 1 说明了我们的 3D 策略。
- 显存效率:先将模型的各层划分到不同的流水线阶段,并进一步把每个阶段的层通过模型并行进行划分。这种 2D 组合同时减少了模型、优化器和激活函数所消耗的内存。不过,我们不能在不引入通信开销的情况下无限地划分模型,而通信开销会限制计算效率。
- 计算效率:为了在不牺牲计算效率的情况下将 worker 数量扩展至超出模型和流水线并行能支持的规模,我们使用了 ZeRO 支持的数据并行功能(ZeRO-DP)。ZeRO-DP 不仅可以通过划分优化器状态量进一步提高显存利用效率,而且还可以通过利用基于通信拓扑的映射关系,以最小的通信开销扩展到任意数量的 GPU。
- 基于通信拓扑的 3D 映射(图2):通过利用两个关键的架构属性,我们将 3D 并行中的每个维度仔细地映射到 worker 上,以实现最大的计算效率。
- 优化节点内和节点间的通信带宽:模型并行是这三种策略中通信开销最大的,因此我们优先考虑将模型并行 worker 组放置在节点内以利用更大的节点内带宽。这里我们基于英伟达 Megatron-LM 进行了张量切分式的模型并行。当模型并行组不占满节点内的所有 worker 时,我们选择将数据并行组放置在节点内。不然就跨节点进行数据并行。流水线并行的通信量最低,因此我们可以跨节点调度流水线的各个阶段,而不受通信带宽的限制。
- 通过并行通信增大带宽:每个数据并行组需要通信的梯度量随着流水线和模型并行的规模线性减小,因此总通信量少于单纯使用数据并行。此外,每个数据并行组会在局部的一小部分 worker 内部独立进行通信,组间通信可以相互并行。这样的结果是,通过减少通信量和增加局部性与并行性,数据并行通信的有效带宽被增大了。
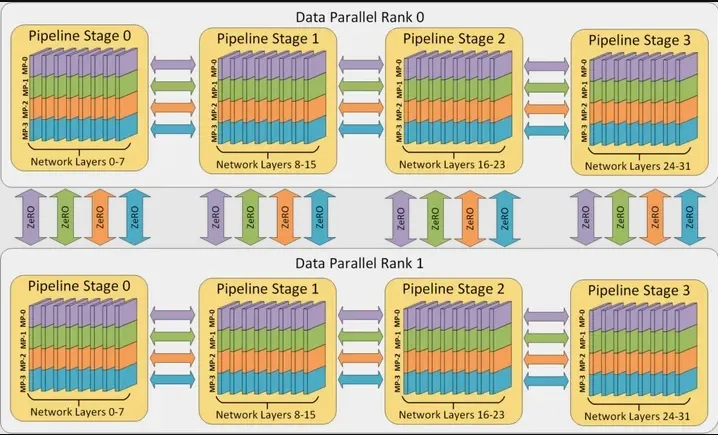
该图显示了一个有 32 个 worker 进行 3D 并行的例子。神经网络的各层分为四个流水线阶段。每个流水线阶段中的层在四个模型并行 worker 之间进一步划分。最后,每个流水线阶段有两个数据并行实例,且 ZeRO 在这 2 个副本之间划分优化器状态量。
图 1:一个有 32 个 worker 进行 3D 并行的例子。神经网络的各层分为四个流水线阶段。每个流水线阶段中的层在四个模型并行 worker 之间进一步划分。最后,每个流水线阶段有两个数据并行实例,且 ZeRO 在这 2 个副本之间划分优化器状态量。
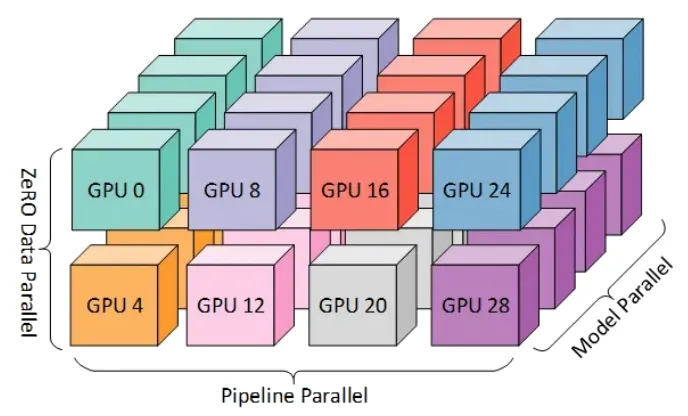
彩色块显示图 1 中的 worker 到八个节点(每个节点有四个 GPU)的系统上的 GPU 的映射。同一颜色的 GPU 在同一节点上。
图 2:图 1 中的 worker 到八个节点(每个节点有四个 GPU)的系统上的 GPU 的映射。同一颜色的 GPU 在同一节点上。
了解关于 3D 并行训练万亿参数模型的更多信息
使用 8 路模型并行,64 路流水线并行和 8 路数据并行,可以在 4096 个英伟达 A100 GPU 上扩展训练一个万亿参数模型。
通过结合模型并行和流水线并行,3D 并行可实现出色的内存效率和跨多个节点的高效计算效率。模型并行性提高了节点内的激活内存和模型状态量的存储效率,而流水线并行,相较于仅使用模型并行,则可以在不牺牲计算效率的情况下,跨节点高效存储模型状态。在 micro-batch 大小为 1 的万亿参数例子中,在使用激活值 checkpoint 以及上述 3D 并行后,模型状态量会消耗 30 GB 的显存,划分后的激活值消耗 2.5 GB 的内存。这样总显存占用为 32.5 GB,就能够使用具有 40 GB 内存的英伟达 A100 GPU 来容纳和训练这样的模型了。
结合模型并行与流水线并行,可以使流水线并行在非常小的 batch 下以最小的 bubble overhead 实现高计算效率。在 8 路模型并行下,每个模型使用 micro-batch 为 1 个微批处理将导致每个 GPU 的有效 micro-batch 大小为 1/8。因此,使用 8 倍于管道并行度的梯度累加步骤,只会让每张 GPU 上的总累计 batch 大小为 1,并且流水并行处理可以实现 90% 的计算效率。与数据并行性结合使用时,这让 4096 张 GPU 上的总有效 batch 大小为 4096,并仍然可以达到 90% 的流水线效率。
但是数据并行会怎样影响计算效率呢?难道数据并行不是需要每张 GPU 都有大 batch 才能保持高效吗?
模型并行可以将每张GPU上的有效 batch 大小减小到小于 1。这使流水线并行即使在小 batch 下仍可以隐藏流水线 bubble overhead。请注意,通过跨节点使用流水线并行性,我们就可以让流水线每个阶段的数据并行节点之间的独立进行通信,并且与其他流水线阶段并行进行。实际上,在高端 GPU 集群中常见的完全连接的网络拓扑中,这对可用于数据并行训练的有效通信带宽具有重要意义。由于流水线阶段中的每个节点都可以与其对应的数据并行节点并行通信,因此有效的通信带宽与流水线阶段数成正比。通过设置64个并行流水线阶段,有效带宽将变为往返单个节点的带宽的 64 倍。流水线并行带给数据并行如此大的有效带宽,这使数据并行在计算与通信比率非常低的小 batch 情况下,也能实现高效扩展。
在线性扩展性下训练万亿参数模型
DeepSpeed 可以只用 800 张英伟达 V100 GPU 来训练具有一个万亿参数的语言模型(图 3)。我们展示了模型大小和训练吞吐量,可以观察到显存和计算效率同时随模型的大小的扩展线性增长。在各种配置中,我们可以在每个 GPU 上训练大约 14 亿个参数,这是单个 GPU 在不耗尽内存的情况下可以支持的最大模型大小,这表明了完美的显存扩展性。我们还获得了接近完美的线性计算效率扩展,每张 V100 GPU 的吞吐量为 47 Tflops。对于上述的硬件,这是令人印象深刻的扩展性和吞吐量。
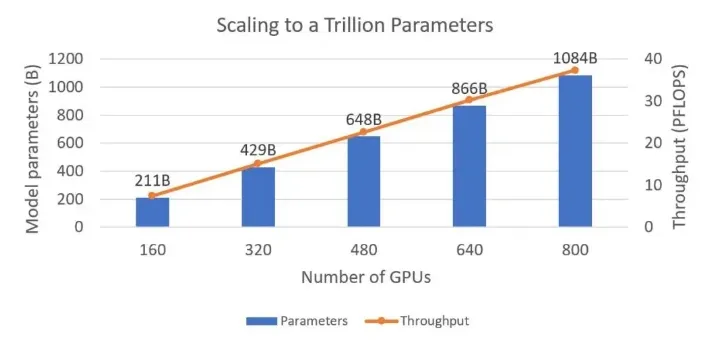
图3:模型大小(以十亿个参数为单位)和训练吞吐量(以 Pflops 为单位)随 GPU 数量变化趋势的图表。DeepSpeed 可以使用 800 张具有 32 GB 内存的英伟达 V100 Tensor Core GPU 训练有 1 万亿个参数的模型。每种配置都使用 NVIDIA Megatron-LM 提供的16路模型并行性,剩余的GPU负责进行流水线并行。万亿参数模型具有 298 层 Transformer,其隐藏层大小为 17408,训练的序列长度为 2048,batch 大小 2048。对于较小的模型,我们根据 GPU 数量按比例减少了 Transformer 层的数量和 batch 大小。
深入研究 3D 并行如何加速训练 GPT-3 规模的模型
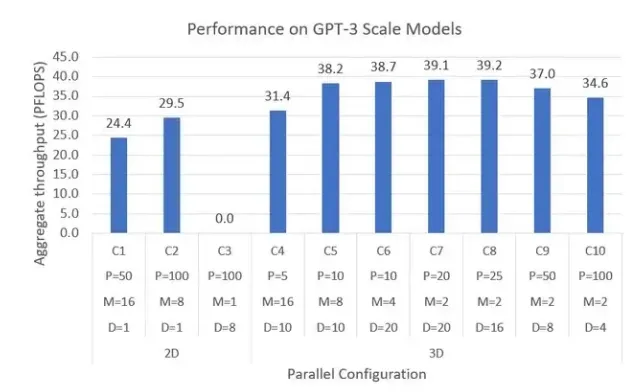
图 4:使用 2D 和 3D 并行使用 800 个 GPU 训练具有 1800 亿参数的 GPT-3 规模模型的系统性能。该模型具有 100 个 Transformer 层,隐藏层尺寸为 12288 并有 96 个 attention head。训练使用的 batch 大小为 2048,序列长度为 2048。ZeRO-1 也可以跟数据并行结合使用。P、M 和 D 分别表示流水线,模型和数据并行维度。
在图 4 中,我们使用具有超过 1,750 亿个参数的最新 GPT-3 模型架构作为 3D 并行性的基准:
- 我们首先评估了 2D 配置(C1-C3)。配置 C1 和 C2 仅使用流水线和模型并行——它们可以训练模型,但由于过度分解模型导致吞吐量较低,GPU 利用率较低。C3 尝试仅使用流水线和数据并行,但不通过 Megatron 的模型并行来减少激活量,就无法解决显存不足的问题。
- 3D 配置(C4-C10)依次增加了流水线并行度;中间的平衡了并行性的配置可以实现最佳性能,实现了显存,计算和通信效率三高。 最佳的 3D 方法每个GPU可实现 49 Tflops,超过硬件的理论峰值的 40%。
看看混合并行如何在低带宽集群上 7 倍加速训练 GPT-2
我们训练了一个 15 亿参数的 GPT-2 模型,并在图 5 中展示了混合并行的通信优势。为了突出展示训练的通信阶段,训练在节点间带宽较低的四节点的群集上进行:
- 模型并行在这种情况下没有优势,因为模型较小,且节点内带宽较低。
- 流水线并行的通信量比配置数据和模型并行的情况小一个数量级。在 batch 较小时,训练速度快 7 倍。
- 数据并行使用通过梯度累积增加 batch 大小来均摊通信开销,但是在更大的 batch 大小下,配置了流水线并行的情况的性能仍是数据并行的两倍。
- 混合流水线和数据并行配置通过将数据并行组限制在节点内的 GPU 上,避免了梯度通信瓶颈,因此梯度通信受益于更快的节点内带宽。
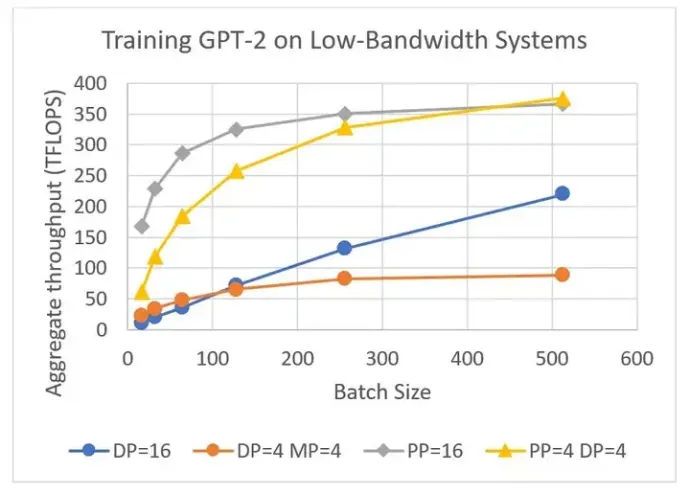
图 5:在训练序列长度为 1024 的 GPT-2(1.5B 参数)时,吞吐量与 batch 大小的关系。使用四个节点,每个节点配备四个具有 16 GB 内存的 V100 GPU 训练。GPU 之间用每秒 50 Gbps 的节点内带宽和 4 Gbps 的节点间带宽连接。DP 表示启用 ZeRO-1 的数据并行性。所有方法都通过增加梯度累积的步数来扩展批量大小。
ZeRO-Offload:单 GPU 训练 10 倍大的模型
ZeRO-Offload 通过同时利用GPU和宿主机 CPU 的计算和存储资源,提升了较少的 GPU 资源下可以高效训练的最大模型规模。它让我们可以在单张 V100 上进行最高至 1300 亿参数的模型训练,10 倍于当前最高水平,同时保持每 GPU 30Tflop 的高训练吞吐量。
通过使单 GPU 具备训练数十亿参数的模型的能力,ZeRO-Offload 让大模型训练变得亲民,让硬件资源有限的深度学习从业者也能参与其中。
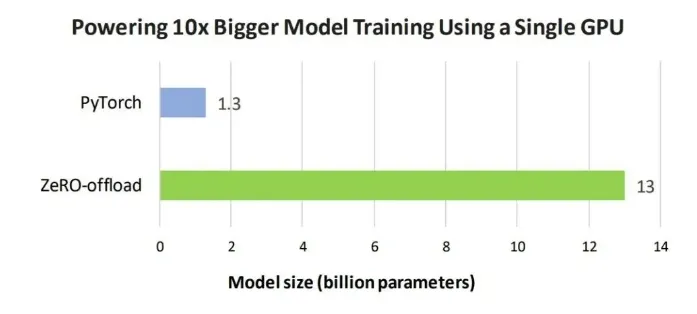
在单 GPU 上使用默认的 PyTorch 和 ZeRO-Offload 能训练的最大模型规模的柱状图。
图 6:可以在单 GPU 上使用默认的 PyTorch 和 ZeRO-Offload 训练的最大的模型规模。
ZeRO-Offload 背后的核心技术是在 ZeRO-2 的基础上将优化器状态和梯度卸至 CPU 内存。这个方法让 ZeRO-Offload 能最大程度降低拷贝至 CPU 导致的计算效率损失,同时达到和 ZeRO-2 相同,甚至有时超过的效率。下图展示了 Zero-OffLoad 的架构:
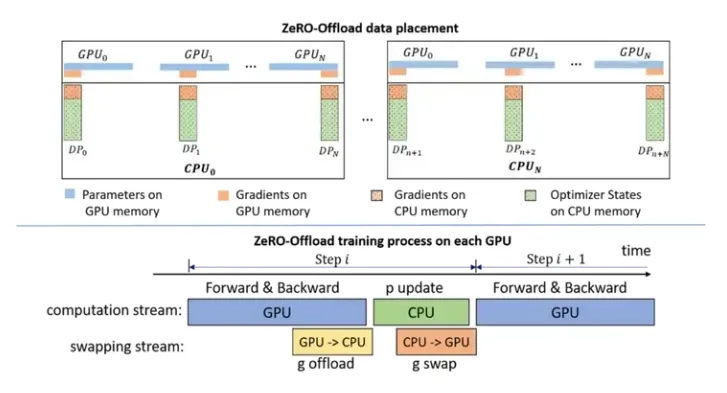
图7: ZeRO-Offload 概述。
了解 ZeRO-Offload 是如何在单GPU上训练数十亿参数模型的
训练 GPT 和 T5 这样有数十亿参数的模型需要多个 GPU 来存储模型和状态量。大模型训练大多通过跨 GPU 的模型并行来解决显存限制问题。最近,我们发布了 ZeRO,一个高效利用显存的优化器,它会将模型状态量(优化器状态量、梯度和模型参数)分布在多个并行 GPU 上,让数十亿参数模型可以在不使用模型并行的情况下进行训练。然而,ZeRO 还是需要大量数据并行的 GPU 来保存划分后的模型状态量,因此只有少数人有条件进行这种模型训练。
ZeRO-Offload 让单 GPU 可以进行大模型训练,从而使这种训练变得平民化。为了在不使用多个 GPU 的情况下训练数十亿个参数的模型,ZeRO-Offload 继承了 ZeRO-2 的划分优化器状态量和梯度的方法。和 ZeRO-2 不同之处在于,ZeRO-Offload 并没有在每个 GPU 上保存一部分优化器状态量和梯度,而是把两者都移到了本机内存上。Optimizer 状态在整体训练过程中都保存在内存中。梯度则是在反向计算过程中在 GPU 上进行计算并通过 reduce-scatter 进行平均,之后每个数据并行进程把自己的那份平均后的梯度卸到 CPU 上(图7中的 g offload)并弃掉不属于自己负责的部分。
一旦梯度到了 CPU 上,划分后的优化状态量就会并行地在 CPU 上进行更新(图7中的 p update)。在更新进行完后,划分后的参数就被移回GPU并用 all gather 操作进行更新 (图7中的 g swap)。Zero-Offload 也通过使用不同 CUDA stream 来重叠通信(如 g offload 和 g swap)和计算(如反向传播和 p update) 以提高训练效率。
从模型规模,训练速度和扩展性看 ZeRO-Offload 的优势
10 倍模型扩展:在单张 32GB V100 GPU 上,图 6 显示 PyTorch 能最多训练有 13 亿个参数的模型,而 ZeRO-Offload 能训练 130 亿个参数的模型,是 PyTorch 的 10 倍。这是因为 ZeRO-Offload 在整个训练过程中将消耗了大部分 GPU 显存的优化器状态保留在本机内存中,同时还在反向传播过程中将计算出来的梯度移至 CPU。因此,节省的 GPU 显存可用于训练更大的模型。
高效的训练吞吐量:如图 8 所示,在训练 100 亿参数模型时,即使仅使用单个 GPU 进行训练,使用 ZeRO-Offload 仍可让每个 GPU 有超过 30 Tflops 的吞吐量,并且其吞吐量随 GPU 数量增长呈近完美的线性增长。
ZeRO-Offload 是 ZeRO-2 的完美补充,支持在少量 GPU 上高效训练大型模型。通过利用 CPU 内存来减少了模型所需的 GPU 显存,ZeRO-Offload 让在 1 到 16 个 GPU 上训练大模型变得可行。在 32 个 GPU 上,ZeRO-Offload 的性能略高于 ZeRO-2; 性能提升来源于 ZeRO-Offload 节省的 GPU 显存,它们让我们可以在更大 batch 下训练了模型,因此尽管存在拷贝至 CPU 的开销,GPU 计算效率仍然可以提高。在有更多的 GPU(例如 64 和 128)的情况下,ZeRO-2 的性能优于 ZeRO-Offload,因为两者现在都可以运行类似大小的batch,ZeRO-2 没有将数据移至 CPU 的开销,并且 GPU 上进行优化器更新要比 CPU 上快得多。总而言之,ZeRO-Offload 是 ZeRO-2 的补充,并扩展了 ZeRO 家族的优化范围,从单台设备到数千台设备,都有大型模型训练的优化方案。
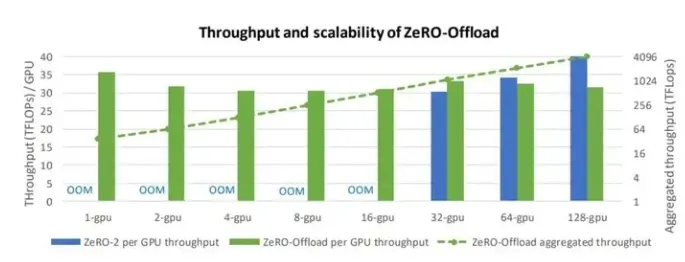
使用 ZeRO-Offload 和 ZeRO-2 在 128 张 GPU 上训练有 100 亿参数的 GPT-2 模型的的吞吐量的柱状图。
图 8:使用 128 张 GPU 训练 100 亿参数 GPT-2 模型的 ZeRO-Offload 和 ZeRO-2 的训练吞吐量比较。
DeepSpeed 稀疏注意力机制:以 6 倍快的速度执行 10 倍长的序列
基于注意力机制的深度学习模型(例如,Transformers)在捕获输入序列中的 token 之间的关系(即使是两者之间距离很长)方面非常有效。因此,它们常与文本,图像和语音相关的输入配合使用。这些输入的序列长度可至数千 token。然而,尽管注意力模块有效地捕获了长序列内的依赖关系,在实际应用中,对长序列输入的支持受计算量和显存的限制。计算量和显存需求关于序列长度(n)呈二次方级增长。
为了解决此限制,DeepSpeed 提供了一套稀疏注意力 kernel——它是一种工具性技术,可以通过块状稀疏计算将注意力计算的计算和显存需求降低几个数量级。这套工具不仅缓解了注意力计算的内存瓶颈,而且其稀疏计算非常高效。它的 API 可以方便地集成进任何基于 Transformer 的模型。除了提供各种稀疏结构外,它还可以灵活处理任何用户自定义的块状稀疏结构。
更具体地说,稀疏注意力(SA)可以设计计算靠近的 token 之间的局部注意力,或通过使用局部注意力计算得到 summary token,进而得到全局注意力。此外,SA 既支持随机注意力,也支持局部、全局和随机注意力的任意组合,如图 10 中的蓝色,橙色和绿色块。这使SA将内存占用减小到(O(wn)),其中1(<w≤n )是一个参数,其值取决于注意力结构。
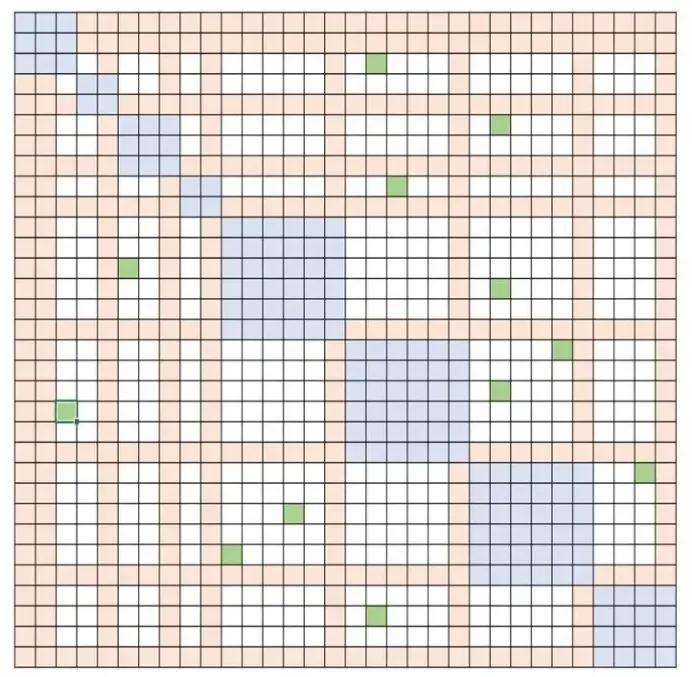
彩色小方块显示可变的稀疏度结构
图 10:可变稀疏结构
在 GPU 上的高效实现:尽管稀疏注意力的基本实现会节省显存,但在计算上,它可能会比稠密计算要差。这主要是由于稀疏数据导致了内存访问的分散性。开发高效的稀疏内核通常是颇具挑战性的,尤其是在 GPU 上。DeepSpeed 提供了在 Triton 中开发的高效的稀疏注意力 kernel。这些 kernel 呈块状稀疏范式结构,可实现对齐的内存访问,减少GPU线程分支并平衡处理器上的工作负载。
系统性能:如图11所示,SA 支持 10 倍长的序列和最高 6.3 倍的计算提速。左图显示了可在 BERT-Base 和 BERT-Large 中运行的最长序列长度。我们的实验有以下三种设置:稠密模式,具有激活 checkpoint 的稠密模式和具有激活 checkpoint 的稀疏(SA)模式。与 BERT-Base 和 BERT-Large 的稠密模式相比,SA 的序列分别长 10 倍和 16 倍。 此外,与稠密模式相比,SA 减少了总计算量,并提高了训练速度:提高的效率随着序列长度的增加而提高,对于 BERT-Base 而言,提升速度高达 6.3 倍,而对于 BERT-Large,则高达 5.3 倍。
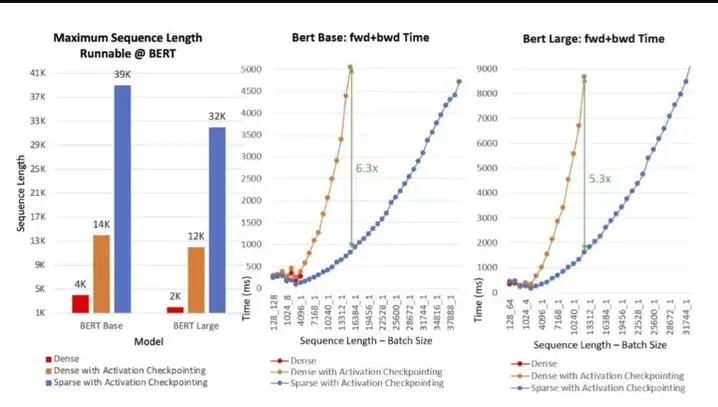
图11:BERT 模型的可支持的最大序列长度(左);在单英伟达 V100 GPU 上训练具有不同序列长度的 BERT-Base(中)和 BERT-Large(右)的时间。
了解 SA 如何使其准确率与全稠密注意力相当甚至比它更高
涉及稀疏注意力的相关工作(Sparse Transformer,Longformer,BigBird)均显示出比全注意力更高的准确性,与我们的经验一致。除了降低内存开销和加快计算速度外,我们还在生产模型中观察到 SA 有更高准确性并更快收敛的情况。下图说明了训练基于 BERT 的长文本理解(序列长度 2048)生产模型的准确性。该实验在以下三种设置中进行:从头开始进行稠密训练,从头开始进行 SA 训练,以及从使用序列长度为 512 的密集型 checkpoint 继续进行 SA 训练。我们已经观察到,对于从头开始进行预训练,SA较于稠密设置收敛的速度更高,精度更好。此外,就时间和准确性而言,从用 SA 继续训练预先训练好的 checkpoint 的效果甚至更好。
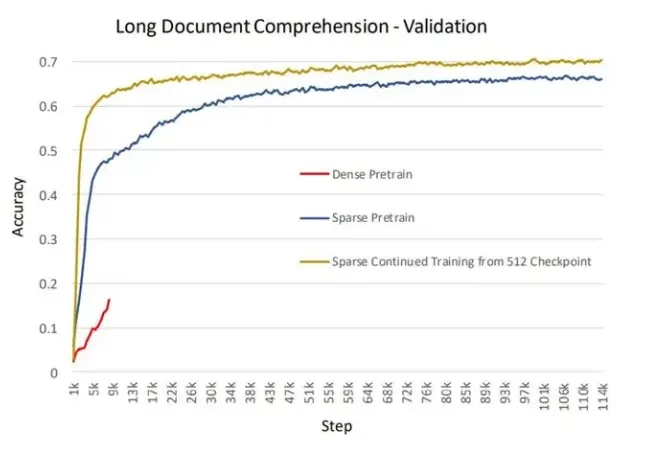
图12:长文本理解应用的准确性
了解 SA 与最新的 LongFormer 的比较情况
我们将 SA 与 Longformer(一种最新的稀疏结构及其实现)进行了比较。在我们的实验中,SA 使用“Fixed”稀疏性。两种实现的准确性相当。在系统性能方面,SA在训练和推断方面均优于Longformer:
- 运行 Wikitext103 上的预训练MLM的速度提高了 1.5 倍
- BERT-Base 的推理速度提高3倍(batch 大小 1,序列长度 2,048)
处理任何块状稀疏结构的灵活性: DeepSpeed 稀疏注意力套件不针对任何特定的稀疏结构, 因此它能有效支持模型研究人员探索任何块状稀疏结构。当前,我们添加了流行的稀疏结构,例如 Fixed(来自OpenAI稀疏Transformer),[BigBird](https://arxiv.org/pdf/2007.14062 .pdf)(来自Google)和BSLongformer(AI2 Longformer的块稀疏实现)。我们还定义了一个具有“可变”结构的模板,如图 10 所示,该模板可用于简单地自定义任何随机,局部或全局注意力模式的块状稀疏结构。
1 比特 Adam:减少5倍的通信量并提升 3.4 倍的训练速度
大型模型(如 BERT 和 GPT-3)的扩展训练需要基于模型设计,体系结构和系统功能的细致优化。从系统的角度来看,通信效率已成为主要的瓶颈,尤其是在使用标准 TCP 且网络带宽有限的商用系统上。
通信压缩是减少在此类系统上的训练时间的重要技术。压缩通信的最有效方法之一是误差补偿压缩,即使在1比特压缩下,它也可以提供稳定的收敛速度。但是,最新的误差补偿技术仅适用于一些和梯度线性相关的简单优化器,例如随机梯度下降(SGD)和 Momentum SGD。这些技术无法和 Adam 之类的非线性优化器整合,后者在许多任务(包括训练类似 BERT 的模型)中带来了最好的收敛率和精度。
对于像 Adam 之类的强大优化器而言,由于它依赖于梯度的非线性特征(在方差项上),针对它来开发基于误差补偿的压缩技术是一项颇具挑战性的工作,因此限制了先进的通信压缩技术的实用价值。
理解经典压缩技术的背景
通信压缩的一种方法是1比特压缩,它可以被表示为:
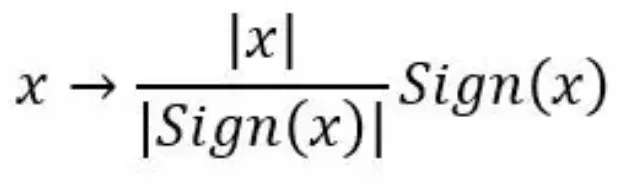
在这种压缩中,我们用 1 比特表示每个数字,从而将内存需求减少 32 倍。问题在于,这种直接的方法会大大降低收敛速度,没什么实用价值。最近的研究表明,通过使用误差补偿压缩,我们有望在通信压缩下保证几乎相同的收敛率。
误差补偿的思想可以概括为:1)进行压缩,2)记忆压缩误差,然后3)在下一次迭代中把压缩误差加回来。对于 SGD,误差压缩相当于:
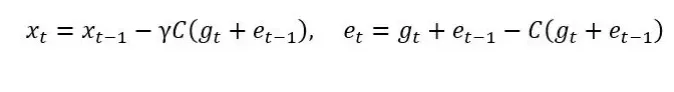
其中(C(⋅))是1比特压缩算子。这种误差压缩的优点在于压缩误差的历史值(e_t)和(e_t-1)最终会相互抵消, 这使得:
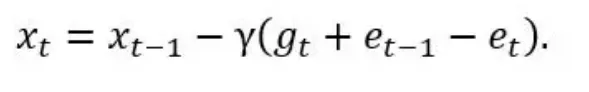
该策略已经被证明适用于所有线性依赖于梯度的优化算法,例如 SGD 和 Momentum SGD。
了解将误差补偿应用于 Adam 的挑战
我们在下面提供了 Adam 算法的概述。更新规则如下:
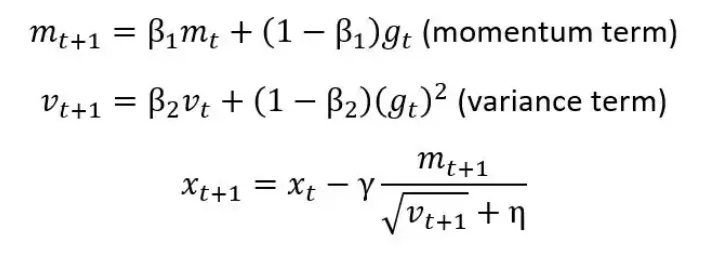
如上图的公式所示,方差项 (v_t) 和梯度 (g_t) 呈非线程关系。如果我们对 Adam 进行普通的误差补偿,我们会发现(见图 13)Adam 将无法收敛。
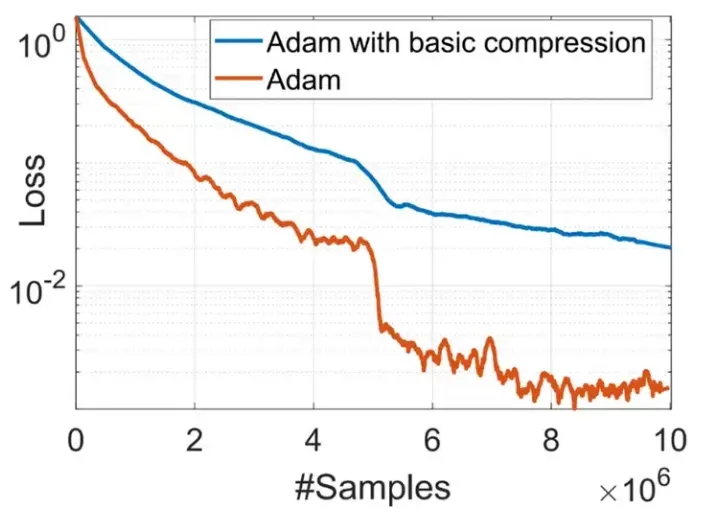
图13:由于对梯度的非线性依赖,误差补偿压缩不适用于 Adam
用 1 比特 Adam 压缩通信
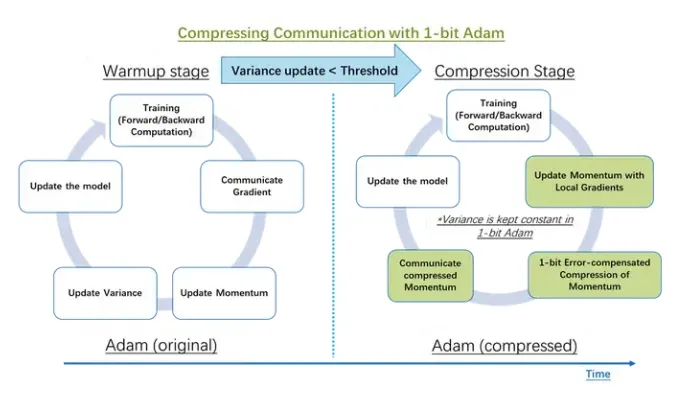
为了在使用 Adam 优化器时压缩通信,我们开发了 1 比特 Adam,它通过预处理解决了梯度中的非线性依赖问题。我们观察到非线性项方差((v_t))的变化幅度在几个训练周期后显著降低,之后将 (v_t) 设置为常数不会改变收敛速度。所以提出的 1 位 Adam 优化器由两部分组成(如图 14 所示):预热阶段,本质上就是原始的 Adam 算法。压缩阶段,使方差项保持恒定,并将剩余的线性项(即动量)压缩为 1 位表示形式。
该算法的压缩阶段由阈值参数控制(如图 14 所示)。当我们检测到“方差”的变化降至某个阈值以下时,就切换到压缩阶段。我们的研究表明,热身阶段只需要全部训练步骤的 15-20%。
进一步了解 1 比特 Adam 的底层机制
1 比特 Adam 的权重按以下公式进行更新。对于第 i 个 worker,在压缩阶段:

a screenshot of text
a screenshot of a cell phone
图 14:使用经典 Adam 算法和使用 1 比特压缩 Adam 算法进行分布式训练的流程对比
应对 1 比特 Adam 的系统挑战
除了算法上的挑战外,在训练系统中应用 1 比特 Adam 还有两个系统挑战。首先,我们需要具备将动量转换为 1 比特表示形式的功能的高效 kernel。其次,我们需要高效的通信方案来在不同的 GPU 之间传输压缩后的动量。压缩的目的是减少总体训练时间,以使带宽受限的商品系统可以用来训练大型模型。我们在 DeepSpeed 中解决了这些具有挑战性的问题,并针对在通信效率受限的系统上进行训练的场景,对 1 比特 Adam 实现进行了全面的优化。
1 比特 Adam 在通信受限系统上的优势
1 比特 Adam 提供了和 Adam 相同的收敛能力,并且最多可以减少 5 倍的通信量,用来进行 BERT-Large 预训练任务时,可达最高 3.5 倍的吞吐量,用于 SQuAD fine-tuning 任务时,可达 2.7 倍的高吞吐量。端到端吞吐量的提高来源于在压缩阶段观察到的 6.6 倍(图 15 左)和 6.2 倍(图 15 右)速度提升。值得一提的是,我们的 1 位 Adam 优化器在 40 Gb 以太网系统上的扩展性非常好,其性能可与 Adam 在 40 Gb InfiniBand QDR 系统上的扩展性相媲美。我们注意到,基于 iPerf 基准,40 Gb 以太网上的有效带宽为 4.1 Gbps,而基于 InfiniBand perftest 微基准,InfiniBand 提供了 32 Gbps 的近峰带宽。
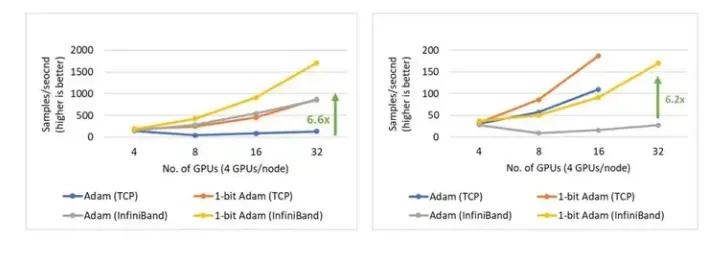
图 15:NVIDIA V100 GPU 上的 BERT-Large 预训练(左)和 SQuAD fine-tuning(右)的 1 比特 Adam 扩展性。BERT 预训练的 batch 大小为 16/GPU,SQuAD fine-tuning 为 3/GPU。
深入研究 1 比特 Adam 的评测结果
与 Adam 相同的收敛性:使用 1 比特 Adam 的一个主要问题是收敛速度。我们发现在使用相同数量的训练样本时,1 比特 Adam 可以达到相同的收敛速度和相当的性能,见图 16。
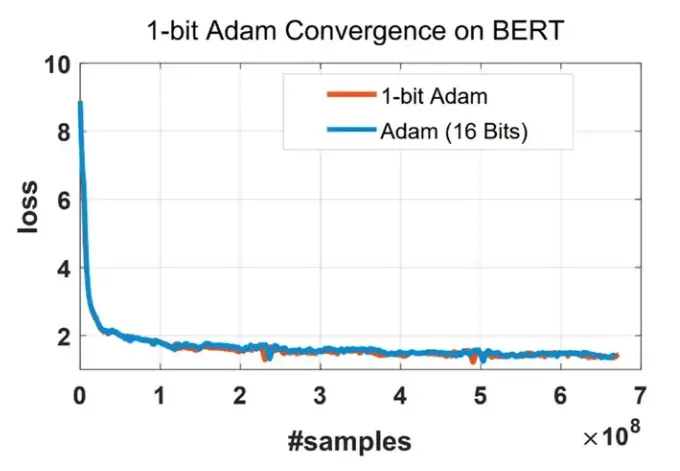
图 16:使用相同数量的训练样本,1 比特 Adam 可以像 Adam 一样收敛。
表 1 显示了 BERT-Base 和 BERT-Large 的详细结果。我们看到,对于未压缩和压缩情况,1 比特 Adam 的性能均与原始模型相当,有些则优于原始模型。
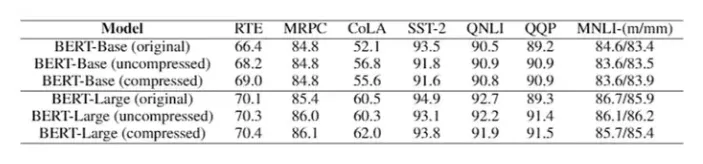
表 1:在各种测试任务上验证 1 比特 Adam 的正确性
最多可减少 5 倍的通信量: 1 比特 Adam 提供了与 Adam 相同的收敛能力,并且在压缩阶段(对于 16 位(FP16)训练)将通信量减少了 16 倍。 对于 BERT 预训练模型,由于我们观察到预热阶段仅为端到端训练时间的 15%,因此总体通信减少了 5 倍。
原始 Adam 和 1 比特 Adam 的通信量之比的公式如下:
1 / (warmup + (1 – warmup)/16)
1 比特 Adam 使训练 BERT-Large 的速度快 3.5 倍: 我们提供了在两个具有有限带宽限制的系统上训练 BERT-Large 的结果:1)40 Gbps 以太网(图 17 左)和 2)40 Gbps InfiniBand QDR(图 17 右)。在压缩阶段,我们发现使用以太网的系统吞吐量提高了 6.6 倍,使用 InfiniBand的系统吞吐量提高了 2 倍,端到端的速度(包括预热和压缩阶段)分别提高了 3.5 倍和 2.7 倍。1 比特 Adam 主要得益于通信量的减少(因为对动量通信的压缩实现)以及我们自定义的 allreduce 操作,该操作通过高效的 1 比特无阻塞 gather 和一个 allgather 操作实现。
值得注意的是,还可以使用 LAMB 而不是 Adam 优化器进行 BERT 预训练,通过增加总 batch 大小以减少通信量。但是,1 比特的 Adam 避免了这种要求严格的超参数调参。根据我们的经验,大 batch 下进行调参通常会更加困难。此外,1 比特 Adam 对于临界批处理量较小(无法在大 batch 下良好收敛,例如许多 fine-tuning 任务)的工作也非常适用。
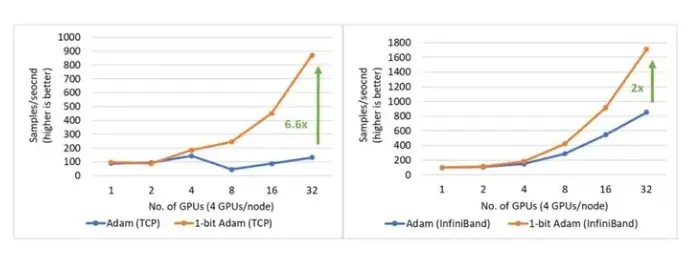
图 17:在压缩阶段,使用 1 比特 Adam 在 40 Gbps 以太网(左)和 InfiniBand(右)上进行 BERT-Large 训练时的性能
1 比特 Adam 使 SQuAD fine-tuning 任务加速 2.7 倍: 1 比特 Adam 不仅在大规模训练任务上提供扩展性,而且在 SQuAD 微调之类的任务上也有效果。如图 18 所示,1 比特 Adam 可在基于以太网和基于 InfiniBand 的系统上很好地扩展,并且在基于以太网的系统上提供高达 6.2 倍的高吞吐量(在压缩阶段),从而带来端到端的 2.7 倍提速(预热阶段占 25%,压缩阶段占 75%)。对于 SQuAD fine-tuning,我们观察到总 batch 大小为 96 时,F1 得分最高。 batch 大小大于此值会降低收敛率,并需要额外的超参数调整。因此,为了扩展到 32 个 GPU,我们在每个 GPU 上运行值为 3-4 的小 batch。这使得 fine-tuning 任务的通信强度大且难以扩展。1 比特 Adam 很好地解决了扩展性的难题,在不增大 batch 的情况下减少了 3.4 倍的通信量,从而实现了 2.7 倍的端到端加速。
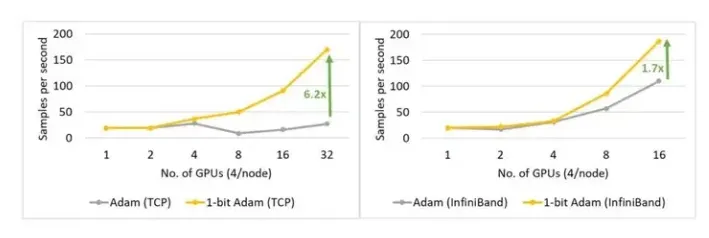
图 18:在 40 Gbps 以太网(左)和 InfiniBand(右)上的 SQuAD fine-tuning 任务中使用 1 比特 Adam 时,压缩阶段的性能。














暂无评论内容