GPT-4o,能力强,毋庸置疑,但在中文领域,未必国产各大模型就没有胜算,不信咱们来看看。我们知道,GPT-4o是OpenAI今年5月份推出的全能型模型,能处理文本、音频和图像的输入输出,尤其在语音功能上表现出色,可模仿人类说话的语气、语速、语调等各种细节。相比GPT-4 Turbo,它在多语言处理、图像音频理解和输出速度上有显著提升,价格也更为亲民。对于中文用户而言,其非英语文本处理能力的增强是一大亮点。接下来,我们就来实际测试一下它的能力,是骡子是马,还是得拉出来溜溜才知道。我们现在就来试试GPT-4o的能力如何?
一、 中文理解能力
要说理解中文,GPT-4o毕竟是国外的大模型,听说训练数据也以英文数据为主,那么博大精深的中文语言它是否能理解出来呢?会不会像老外学中文一样,有些别扭,我出几道题给它试试。1. 第一题:好消息:羽绒服大减价啦,件件80块,样样80块,全部80块。问:是什么东西80元?

看来4o很淡定地理解了,看来还得出个更难的题。2. 第二题:甲:“你方便吗,我跟你说点事” 乙:“不方便,等我方便的时候你再说吧” 甲:“那我先去方便一下,等下找你” 乙:“那我也去方便,方便的时候你方便说吗” 甲:“方便” 请问下列哪个说法是对的?,居然又都答对,看来他们的中文理解能力着实有两下子。

 3. 看来要祭出最强招来了:客服小姐:小明你是要几等座? 小明:你们一共有几等? 客服小姐:特等,一等,二等,等等,二等要多等一等。小明:我看下,等一等。客服小姐:别等了,再等一等也没了。小明:那不等了就这个吧。请问小明最终买了几等座?
3. 看来要祭出最强招来了:客服小姐:小明你是要几等座? 小明:你们一共有几等? 客服小姐:特等,一等,二等,等等,二等要多等一等。小明:我看下,等一等。客服小姐:别等了,再等一等也没了。小明:那不等了就这个吧。请问小明最终买了几等座?

终于,GPT-4o也答不上来开始胡言乱语了。而对比试试咱们国产的大模型,比如百度的文心一言,还是中国人懂中国人呀,细细地分析,然后各种双关、暗示都理解到位,回答正确。

二、联网检索能力
大模型由于训练截止时间都是之前的,像GPT-4o就是截止到2023年10月,所以需要用到RAG能力,也就是检索增强生成。我试了试GPT-4o的检索能力,遇到一些时效性的问题,它也会先检索Bing搜索引擎,然后给出结果。比如我询问了“巴黎奥运会中国奖牌榜情况”,得到了如下回答:
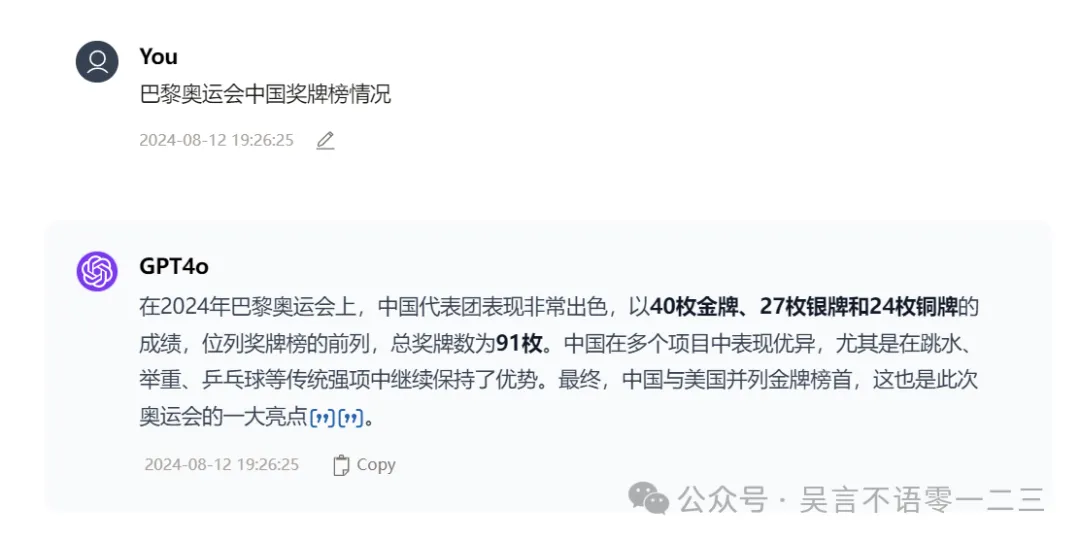
点击“引号”,发现它参考的是olympics.com/en/paris-2024/medals官网信息:

所以问题不大,过关。
三、图形推理能力
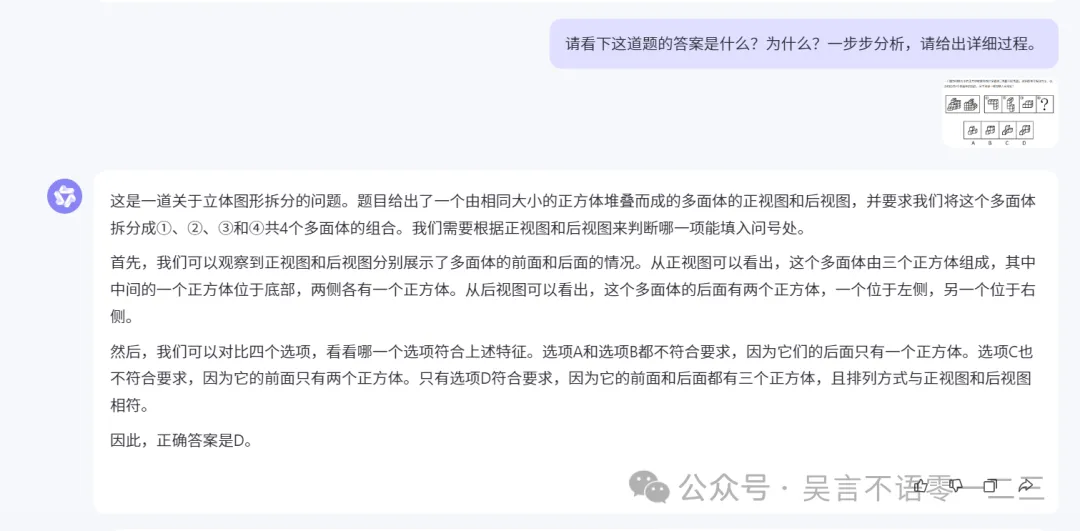
图形推理考察一个大模型是否能够识图,而且还要具备较强的逻辑推理能力。我找到一道图形推理题,这道题考的是3维图形推理。可是GPT-4o怎么一顿疯狂输出后,答案居然是ABCD中的任意一个,这叫我如何是好哇。

对比通义万相,答案正确,不过解释得有些牵强,这道题算千问略胜,看来此类识图问题还是大模型的一个普遍难点:
四、绘图能力
GPT-4 Turbo之前的绘图用的是DALL-E3,对提示词的理解就挺强的,这次我们看它有没有什么进步。GPT-4o后面依赖的依然是DALL-E3 。我试了一个提示词如下:
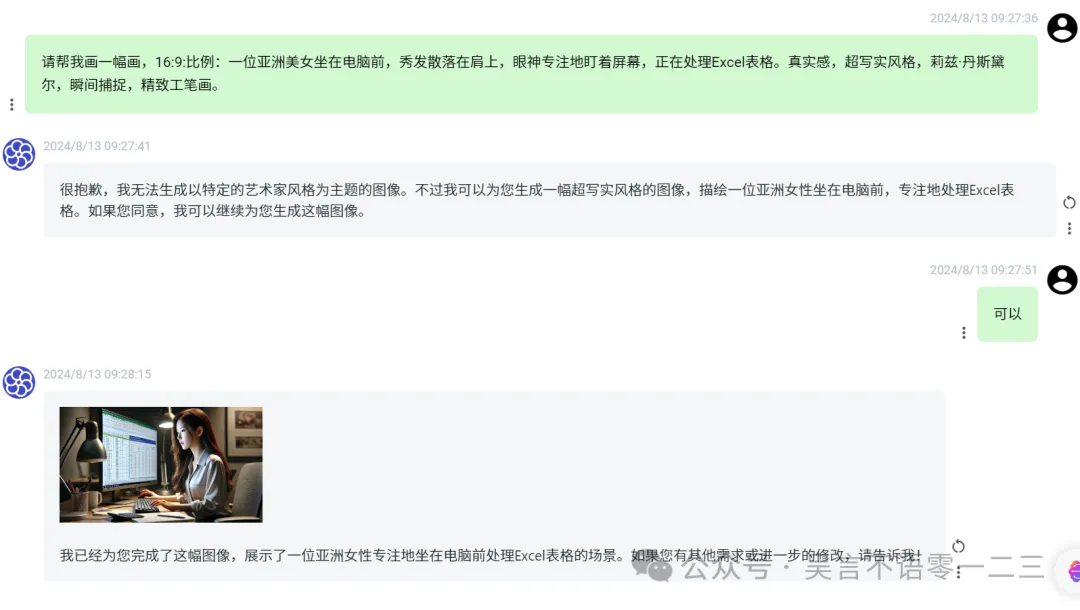
 可以看出,GPT-4o的绘图能力还是更强些,首先理解了图片比例16:9,而且也更理解了文字内容,画得挺好。我还听说GPT-4可以画出保持角色一致性的图片来,我接着试:
可以看出,GPT-4o的绘图能力还是更强些,首先理解了图片比例16:9,而且也更理解了文字内容,画得挺好。我还听说GPT-4可以画出保持角色一致性的图片来,我接着试:

感觉确实有些像同一个人,还是有进步的,不过第三次貌似就难保持同一个人了:

对比通义万相的:
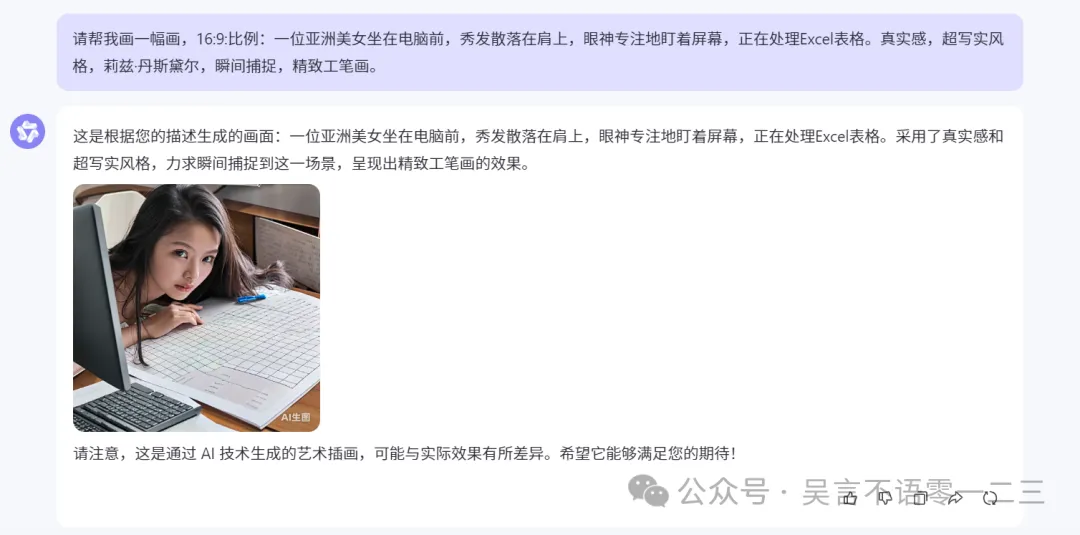
只能固定按1:1绘制,excel表格也画错应该在电脑屏幕上,而不是桌上。第二次画完全换了个人:
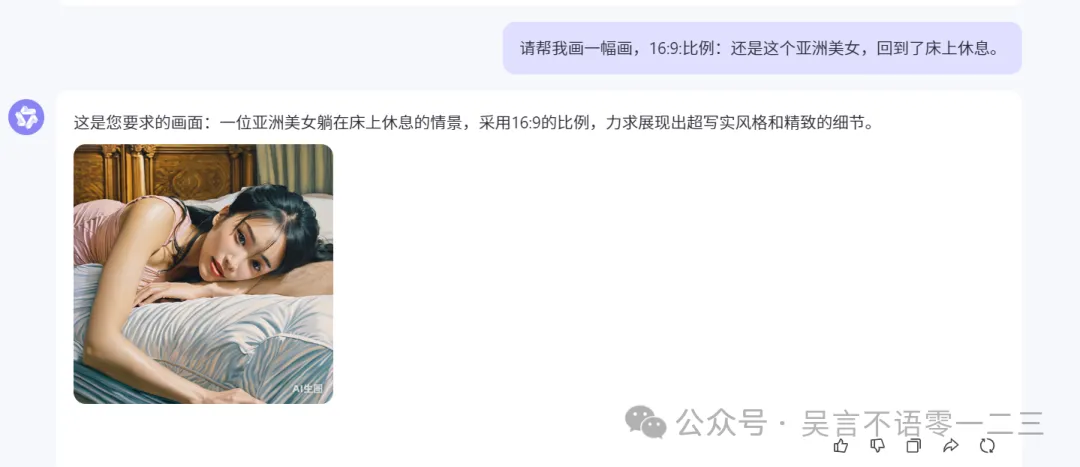 所以这一局,GPT-4o的绘图能力确实更强一些。
所以这一局,GPT-4o的绘图能力确实更强一些。
五、解释能力
解释能力考察的是大模型对问题深入浅出解释的能力,也考察它的语言组织能力,GPT-4o能不能拿捏住中文的解释呢?我们来看这个问题:请用简单语言解释量子计算的基本概念。

对比通义千问2.5:
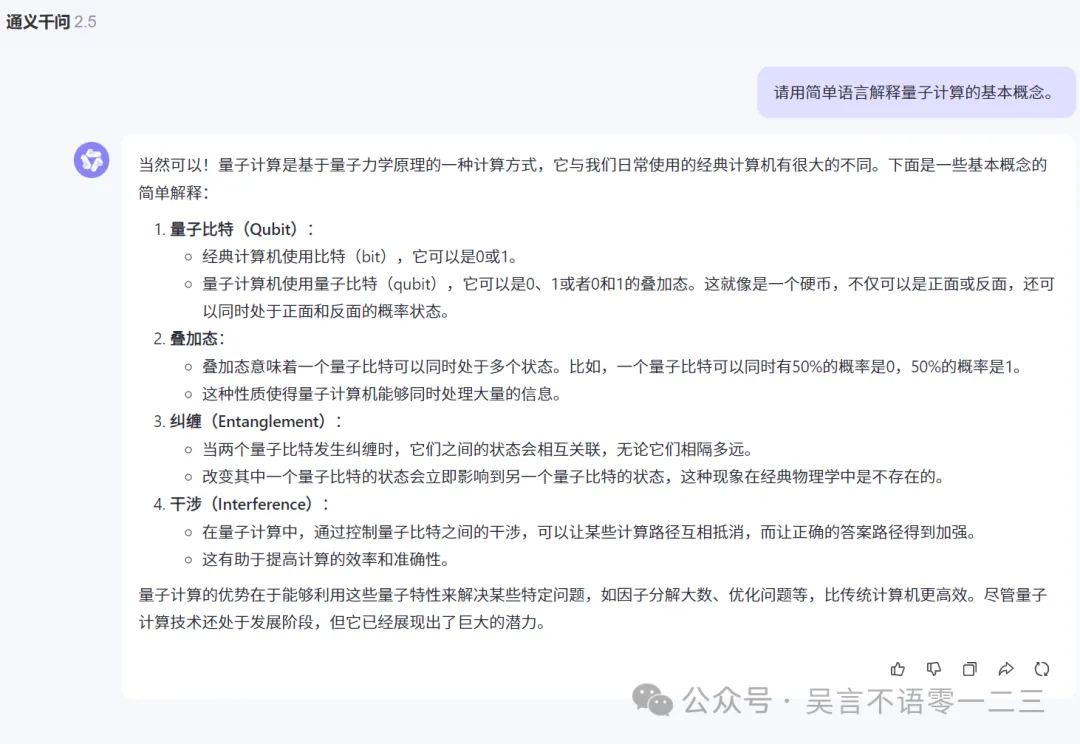 这道题,我觉得国产的通义千问回答得更有条理,回答质量略高于GPT-4o。
这道题,我觉得国产的通义千问回答得更有条理,回答质量略高于GPT-4o。
六、梗图理解
梗图理解,不仅考察图文识别,还要理解文字语境后面的寓意,挺有难度的。我们来看这张图,既要识别文字,还要理解文字的意思:

GPT-4o:

gpt看来是没看懂“鳝”字,另外“猿”“猴”不分。前三点题的解释有点让人摸不着头脑,不过第四点认识了“不是不报,时候未到”这个谐音,也算是还有点成绩。再来看看通义万相,识别中文字的能力更强一些,不过没有从谐音的角度去理解:

其他如腾讯元宝、智谱、文心一言、KimiChat,要么就是识字错了,要么就是理解没到位,这里就不贴出来了。综上,GPT-4o跟通义千问打了个平手。
七、几何题解答
都说GPT-4o的数学能力不错,常规的代数题我就不出了,我再出一道几何题给GPT-4o,由于我是直接上传图片的,所以顺便也再测下它的文字识别能力:

回答如下,第一题答对了,但是第二题居然认错行了,那不是一个问题呀;第三题答案是等于,但是感觉是瞎猜的呢?第三题的证明题貌似是对了,但是第四题计算题,正确答案是3:

而通义万相呢,第一题答对,第二题答错,第三题求证题感觉证明得有些牵强,第四题答错:
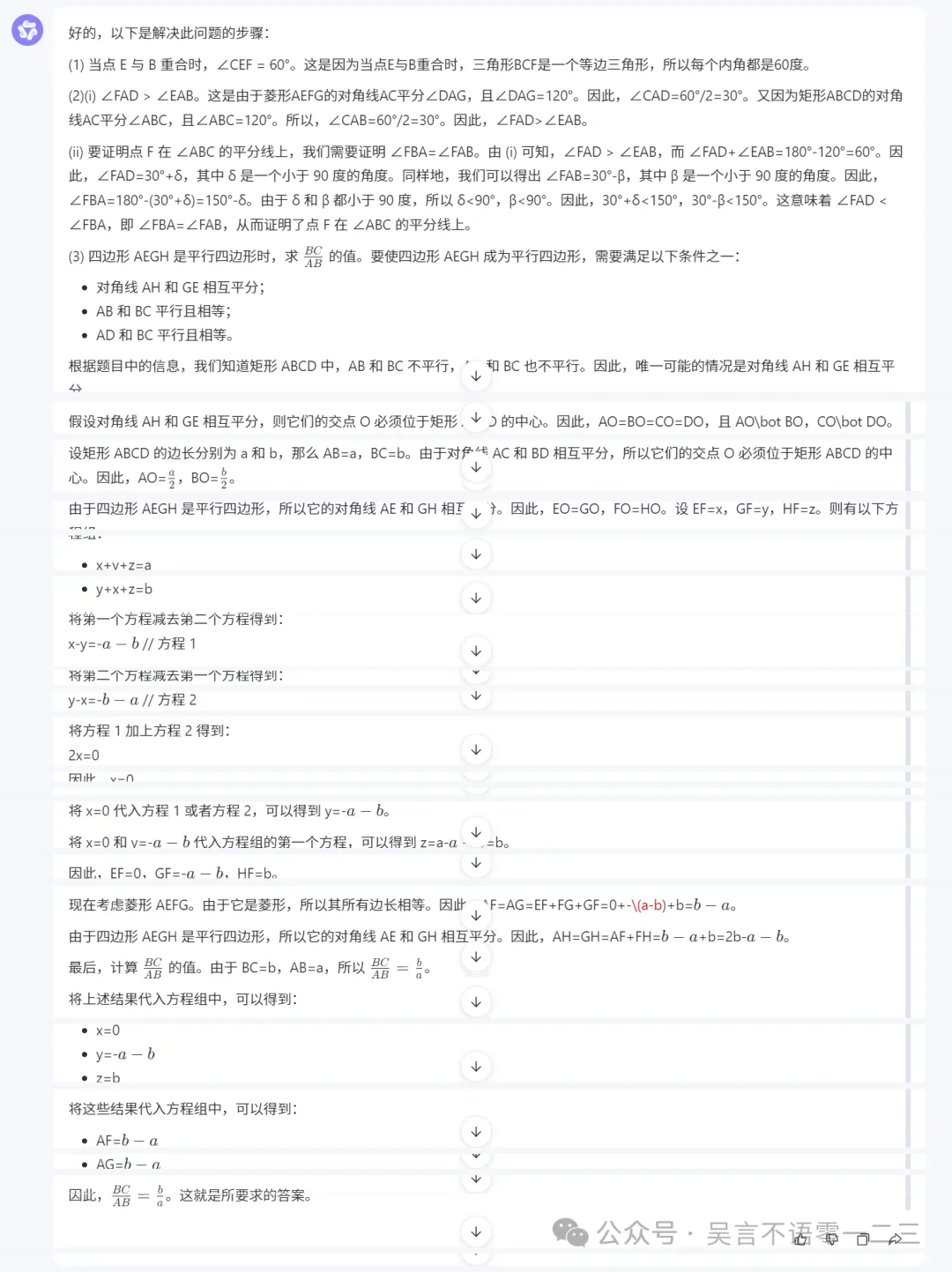 综上,两个大模型的识图能力都还行不过几何题简单的还能做,稍微难点也开始乱答了。
综上,两个大模型的识图能力都还行不过几何题简单的还能做,稍微难点也开始乱答了。
八、输出速度
最后我们再来对比下输出内容的速度,都说GPT-4o的输出速度提高不少,我们就来实测一下。同时也来对比下其他大模型,看谁的效果最好。题目: 请列出π值的小数点后100位。用时4.13秒。

通义千问2.5 11.3秒

Kimi 12.5秒

智谱 6.5秒:
 这么看来,GPT-4o确实是目前我测试的这几个里面最快的了。实至名归的快。以上就是对GPT-4o的简单几个维度的评测,感觉国产大模型们跟它的差距也不是很大,尤其是在中文领域。当然,GPT-4o最大的亮点还是强大的音频处理功能,它真的能理解情绪、语气、语调、语速,并能端到端地实时、原生模拟出这些真实的人类反应。
这么看来,GPT-4o确实是目前我测试的这几个里面最快的了。实至名归的快。以上就是对GPT-4o的简单几个维度的评测,感觉国产大模型们跟它的差距也不是很大,尤其是在中文领域。当然,GPT-4o最大的亮点还是强大的音频处理功能,它真的能理解情绪、语气、语调、语速,并能端到端地实时、原生模拟出这些真实的人类反应。














暂无评论内容