🌟Qwen-Agent是一个开发框架。开发者可基于该框架开发Agent应用,充分利用基于通义千问模型(Qwen)的指令遵循、工具使用、规划、记忆能力。该项目也提供了浏览器助手、代码解释器、自定义助手等示例应用。
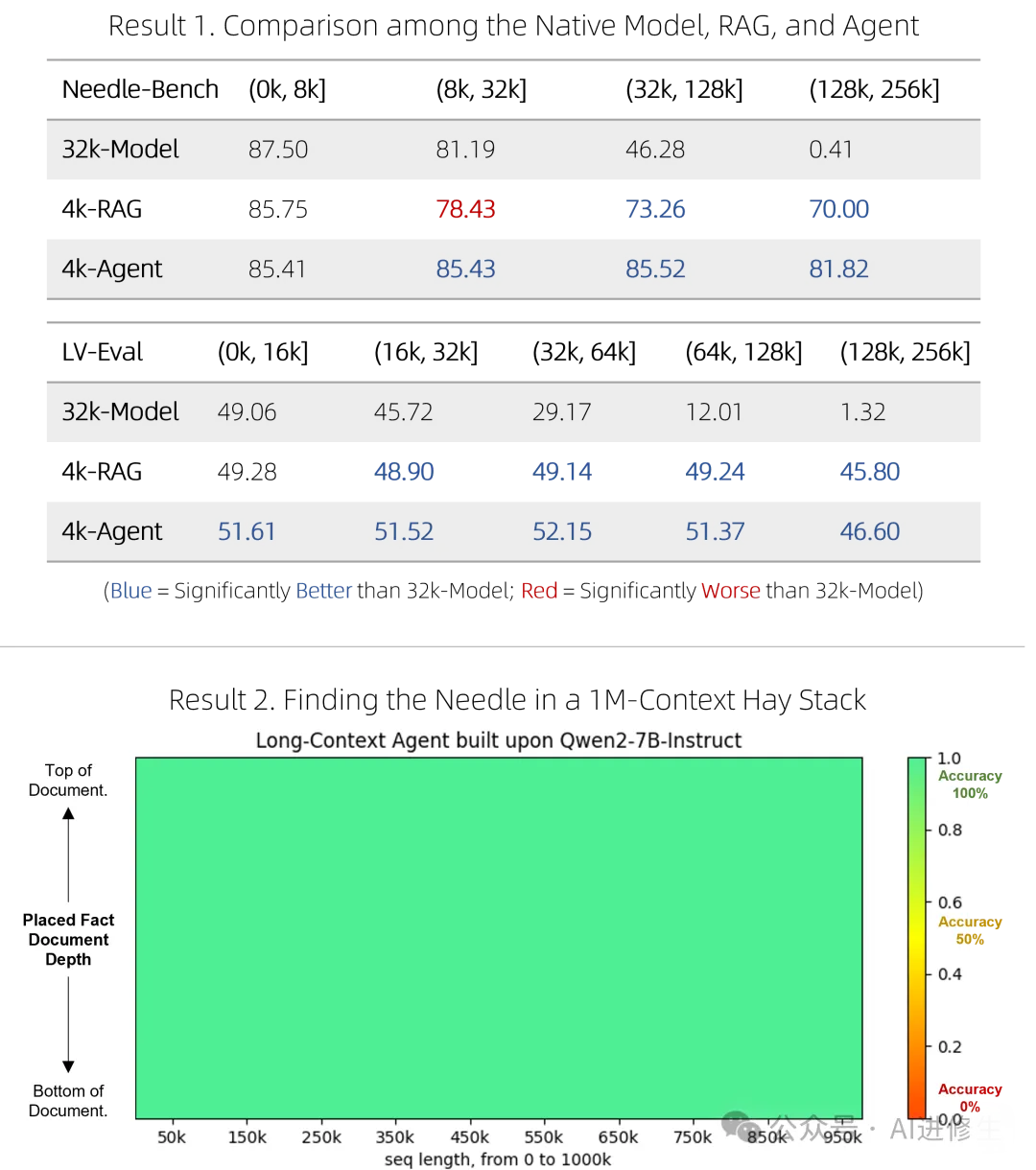
阿里巴巴最近发布了新的 Qwen 2 大型语言模型和升级后的 Qwen Agent 框架,这个框架集成了 Qwen 2 模型,支持函数调用、代码解释、RAG(检索增强生成)等功能,还包含了 Chrome 扩展。Qwen Agent 能处理从 8K 到 100 万 tokens 的文档,性能超越了RAG 和原生长上下文模型,并用于生成训练新长上下文模型的数据。
Qwen Agent 框架可用于创建复杂的 AI 代理,展示了其强大的任务处理能力。新框架采用四步法开发:初始模型开发、代理开发、数据综合和模型微调。通过 RAG 算法处理长文档,将文档分成小块,保留最相关的部分,从而提升上下文处理能力。
具体步骤包括检索增强生成、逐块阅读和逐步推理等三层复杂性,使用 RAG 算法处理并优化文档片段,以便提供准确的上下文理解和生成能力。实验表明,Qwen Agent 能显著提升模型的上下文长度和性能。
建议观看之前的视频以获取更多实用示例,Qwen 2 是目前最强大的开源语言模型之一,推荐尝试使用。框架操作简便,有详细教程帮助用户快速上手。
这一框架的目标是创建复杂的AI代理,其表现优于其他代理框架。下面视频展示了如何利用Qwen-2模型及其8K上下文窗口理解包含百万级词汇的文档,这比RAG和原生长上下文模型表现更好。
Qwen-Agent 开发步骤
1. 初始模型:从8K上下文聊天模型开始。
2. 代理开发:使用模型开发强大的代理,处理百万上下文。
3. 数据合成:合成细化数据,进行自动过滤确保质量。
4. 模型微调:利用合成数据微调预训练模型,最终得到强大的聊天机器人。
分层复杂性
Qwen-Agent在构建过程中分为三层复杂性,每层在前一层基础上构建:
1. 增强型信息检索生成(RAG):使用RAG算法将上下文分成不超过512词的块,仅保留最相关的内容。
2. 逐块阅读:采用暴力策略,每512词块检查相关性,保留最相关的内容生成答案。
3. 逐步推理:使用多跳推理回答复杂问题,采用工具调用代理解决复杂查询。
下面提供官方的文档介绍、相关资源、部署教程等,进一步支撑你的行动,以提升本文的帮助力。
 开始上手
开始上手
安装
• 安装稳定的版本:
pip install -U qwen-agent
• 或者,直接从源代码安装最新的版本:
git clone https://github.com/QwenLM/Qwen-Agent.git
cd Qwen-Agent
pip install -e ./
如需使用内置GUI支持,请安装以下可选依赖项:
pip install -U “gradio>=4.0” “modelscope-studio>=0.2.1”
准备:模型服务
Qwen-Agent支持接入阿里云DashScope服务提供的Qwen模型服务,也支持通过OpenAI API方式接入开源的Qwen模型服务。
• 如果希望接入DashScope提供的模型服务,只需配置相应的环境变量DASHSCOPE_API_KEY为您的DashScope API Key。
• 或者,如果您希望部署并使用您自己的模型服务,请按照Qwen2的README中提供的指导进行操作,以部署一个兼容OpenAI接口协议的API服务。具体来说,请参阅vLLM一节了解高并发的GPU部署方式,或者查看Ollama一节了解本地CPU(+GPU)部署。
快速开发
框架提供了大模型(LLM,继承自class BaseChatModel,并提供了Function Calling功能)和工具(Tool,继承自class BaseTool)等原子组件,也提供了智能体(Agent)等高级抽象组件(继承自class Agent)。
以下示例演示了如何增加自定义工具,并快速开发一个带有设定、知识库和工具使用能力的智能体:
import pprint
import urllib.parse
import json5
from qwen_agent.agents import Assistant
from qwen_agent.tools.base import BaseTool, register_tool
# 步骤 1(可选):添加一个名为 `my_image_gen` 的自定义工具。
@register_tool(‘my_image_gen’)
class MyImageGen(BaseTool):
# `description` 用于告诉智能体该工具的功能。
description = ‘AI 绘画(图像生成)服务,输入文本描述,返回基于文本信息绘制的图像 URL。’
# `parameters` 告诉智能体该工具有哪些输入参数。
parameters = [{
‘name’: ‘prompt’,
‘type’: ‘string’,
‘description’: ‘期望的图像内容的详细描述’,
‘required’: True
}]
def call(self, params: str, **kwargs) -> str:
# `params` 是由 LLM 智能体生成的参数。
prompt = json5.loads(params)[‘prompt’]
prompt = urllib.parse.quote(prompt)
return json5.dumps(
{‘image_url’: f’https://image.pollinations.ai/prompt/{prompt}’},
ensure_ascii=False)
# 步骤 2:配置您所使用的 LLM。
llm_cfg = {
# 使用 DashScope 提供的模型服务:
‘model’: ‘qwen-max’,
‘model_server’: ‘dashscope’,
# ‘api_key’: ‘YOUR_DASHSCOPE_API_KEY’,
# 如果这里没有设置 ‘api_key’,它将读取 `DASHSCOPE_API_KEY` 环境变量。
# 使用与 OpenAI API 兼容的模型服务,例如 vLLM 或 Ollama:
# ‘model’: ‘Qwen2-7B-Chat’,
# ‘model_server’: ‘http://localhost:8000/v1’, # base_url,也称为 api_base
# ‘api_key’: ‘EMPTY’,
# (可选) LLM 的超参数:
‘generate_cfg’: {
‘top_p’: 0.8
}
}
# 步骤 3:创建一个智能体。这里我们以 `Assistant` 智能体为例,它能够使用工具并读取文件。
system_instruction = ”’你是一个乐于助人的AI助手。
在收到用户的请求后,你应该:
– 首先绘制一幅图像,得到图像的url,
– 然后运行代码`request.get`以下载该图像的url,
– 最后从给定的文档中选择一个图像操作进行图像处理。
用 `plt.show()` 展示图像。
你总是用中文回复用户。”’
tools = [‘my_image_gen’, ‘code_interpreter’] # `code_interpreter` 是框架自带的工具,用于执行代码。
files = [‘./examples/resource/doc.pdf’] # 给智能体一个 PDF 文件阅读。
bot = Assistant(llm=llm_cfg,
system_message=system_instruction,
function_list=tools,
files=files)
# 步骤 4:作为聊天机器人运行智能体。
messages = [] # 这里储存聊天历史。
while True:
# 例如,输入请求 “绘制一只狗并将其旋转 90 度”。
query = input(‘用户请求: ‘)
# 将用户请求添加到聊天历史。
messages.append({‘role’: ‘user’, ‘content’: query})
response = []
for response in bot.run(messages=messages):
# 流式输出。
print(‘机器人回应:’)
pprint.pprint(response, indent=2)
# 将机器人的回应添加到聊天历史。
messages.extend(response)
除了使用框架自带的智能体实现(如class Assistant),您也可以通过继承class Agent来自行开发您的智能体实现。更多使用示例,请参阅examples目录。
FAQ
支持函数调用(也称为工具调用)吗?
支持,LLM类提供了函数调用的支持。此外,一些Agent类如FnCallAgent和ReActChat也是基于函数调用功能构建的。
如何让AI基于超长文档进行问答?
我们已发布了一个快速的RAG解决方案,以及一个虽运行成本较高但准确度较高的智能体,用于在超长文档中进行问答。它们在两个具有挑战性的基准测试中表现出色,超越了原生的长上下文模型,同时更加高效,并在涉及100万字词上下文的“大海捞针”式单针查询压力测试中表现完美。欲了解技术细节,请参阅博客。














暂无评论内容