模型性能提升一直是研究者和工程师们追求的目标。

前特斯拉AI总监、OpenAI创始团队成员Andrej Karpathy(@karpathy)在Twitter上分享了他在llm.c项目上的新进展:
llm.c项目在第24天实现了多GPU训练,并在bfloat16格式下,通过flash attention技术,直接在大约3000行C/CUDA代码中实现了快速训练。
他强调,与PyTorch的最新夜间版本相比,llm.c的速度提升了约7%,并且这一比较是在包含了所有现代和标准特性(如混合精度训练、torch编译和flash attention)的情况下进行的。与PyTorch稳定版2.3.0相比,llm.c的速度更是快了约46%。
Karpathy表示,他的目的并非贬低PyTorch,而是想表达llm.c的速度非常快。在过去的1.5周内,llm.c项目取得了显著进展,包括添加了混合精度训练(bfloat16)、多项内核优化(如不实现归一化logits的FusedClassifier)、来自cudnn的flash attention,以及迫使A100利用128位加载(LDG.128)和存储(STS.128)指令的Packed128数据结构。此外,项目还实现了多GPU训练的首版,包括MPI+NCCL的支持,以及即将合并的ZeRO(优化器状态分片)的第一阶段的拉取请求。
Karpathy 提到他们的目标是创建一个可靠、清洁、经过测试、最小化、硬化且足够优化的LLM栈,以在C/CUDA中直接复现GPT-2系列的所有模型尺寸,从124M到1.6B。
关于@pankaj 质疑编译速度的问题,Karpathy 提到他们正在通过一个正在进行的拉取请求删除合作组,并特别提到了对cuDNN的依赖,尽管cuDNN的flash attention内核被使用,但代价很高,他正在考虑其他的解决方案。
下为内容原文:
[2024年5月3日]
这是llm.c项目的第24天。我们现在可以进行多GPU训练,使用bfloat16,并且使用闪存注意力,速度非常快!🚀
单GPU训练。我们现在训练GPT-2(124M)比PyTorch夜间版本快约7%,没有任何限制。即这是我知道的可以在Ampere上配置的最快的PyTorch单GPU训练,包括所有现代和标准的功能:混合精度训练、torch编译和闪存注意力。与当前的PyTorch稳定版本2.3.0相比,我们实际上快了约46%,但PyTorch的团队在过去的大约一个月中忙于合并了许多改进,这些改进大大加速了GPT-2训练设置(非常好!)。最后,与4月22日的最后一个状态报告相比,这是约3倍的速度提升。过去一周里有很多改进,主要包括:
- ✅ 混合精度训练(bfloat16),参数主副本保持在fp32中
- ✅ 内核优化,包括例如一个融合的分类器,这是对PyTorch编译器到目前为止所做的算法改进(我们没有实现标准化的对数并且只在标签的索引处评估损失)
- ✅ 闪存注意力(目前是cuDNN的)
- ✅ Packed128 数据结构(有点像float4但支持混合精度),强制新硬件使用128位加载(LDG.128)和存储(STS.128)指令来最大化内存带宽
- ✅ 内存节省。删除了之前用于反向传播梯度的大量不必要内存,显著降低了训练所需的内存
多GPU训练。已经实现了一个稳定的版本1:
- ✅ 首个多GPU训练版本,使用MPI+NCCL
- ✅ 对整个训练运行进行NVIDIA Nsight Compute分析
- PR即将合并第1阶段的ZeRO(优化器状态分片)
功能性。除了训练效率本身,我们还在为准确复现GPT-2系列模型大小从124M到真正的1.6B做准备。为此我们需要额外的更改,包括梯度累积、梯度裁剪、直接在C中从随机权重初始化、学习率热身和计划、评估(WikiText 103?)和一个现代的预训练数据集(例如fineweb?)。许多这些组件都在等待中,目前正在研究中。
目标。当前的目标是创建一个可靠、稳定、干净、测试、简洁、加固且足够优化的LLM堆栈,可以直接在C/CUDA中复现GPT-2系列的所有模型大小,从124M到1.6B。按照目前的进度,这感觉像是大约2周的时间。
代码行数
👎 随着更多功能和优化,代码行数增加。主代码文件train_gpt2.cu现在约有3,000行代码(LOC)。此外,我们分离出两个新文件common.h(300 LOC)和tokenizer.h(100 LOC),现在我们包括它们。这比4月22日的约2000 LOC有所增加。
延迟
👎 遗憾地报告一些不那么令人振奋的项目编译延迟发展:
- nvcc编译延迟,即time make train_gpt2cu:4.3s(之前为2.4s)。所以,不幸的是,这现在和import torch一样糟糕,我们非常有兴趣了解如何减少这种延迟。
- 打开闪存注意力,即time make train_gpt2cu USE_CUDNN=1包括cudnn闪存注意力并提供了很大的加速和内存节省,但不幸的是使编译延迟增加到约1m24s 🤦♂️。这是我们使用cudnn导致的一次重大而之前未预料到的减速,我们非常有兴趣删除这个依赖。
峰值内存
👍 我们的峰值内存使用量最近通过非常小心地管理我们分配和使用的内存,尤其是通过我们的融合分类器,有了很大的改进。使用批大小32和序列长度1024进行训练。llm.c和PyTorch的示例调用:
make train_gpt2cu USE_CUDNN=1 && ./train_gpt2cu -i data/TinyStories -v 250 -s 250 -g 144 -b 32python train_gpt2.py –write_tensors=0 –num_iterations=1000 –sequence_length=1024 –compile=1 –tensorcores=1 –dtype=bfloat16 –flash=1 –batch_size=32 –input_bin=data/TinyStories_train.bin
llm.c:16.6 GiB PyTorch:37.2 GiB
(诚实地说,这个PyTorch数字在这个比较中感觉有点可疑地高,待办事项,进一步调查并编辑)
运行时间,DRAM流量,指令:
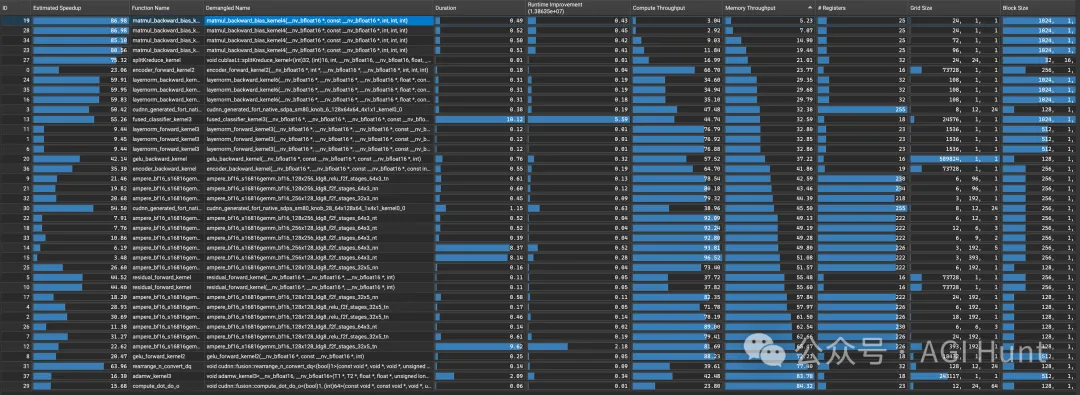
👍 profile_gpt2cu.py的运行(批大小24):
Kernel type summaries: name time frac count ampere_bf16 360.03 55.13% 111 cutlass::Kernel2 109.09 16.70% 36 cudnn_generated_fort_native_sdpa 58.27 8.92% 24 gelu_backward_kernel 20.44 3.13% 12 fused_classifier_kernel3 20.07 3.07% 1 matmul_backward_bias_kernel6 15.49 2.37% 48 layernorm_backward_kernel7 15.28 2.34% 25 adamw_kernel3 14.08 2.16% 1 gelu_forward_kernel2 13.56 2.08% 12 residual_forward_kernel 8.35 1.28% 24 cudnn::fusion::rearrange_n_convert_dq 8.07 1.24% 12 layernorm_forward_kernel3 5.74 0.88% 25 cudnn::fusion::compute_dot_do_o 3.46 0.53% 12 copy_and_cast_kernel 2.86 0.44% 0 encoder_backward_kernel 0.78 0.12% 1 encoder_forward_kernel3 0.26 0.04% 1 cast_and_add_kernel 0.08 0.01% 48
In total, a training step takes 302.5ms, distributed as: 0.2ms (0.1%) in the encoder, 75.0ms (24.8%) in forward blocks, 44.0ms (14.5%) in the classifier part, 183.4ms (60.6%) in backward blocks, and 0.0ms (0.0%) in the optimizer.
We read 113.3GiB (374.4GB/s) and write 68.3GiB (225.6GB/s) to DRAM,read 351.5GiB (1161.9GB/s) and write 70.1GiB (231.8GB/s) to L2,and execute 6.6 billion instructions (21.9 GInst/s).
核心视觉效果,过时1天:
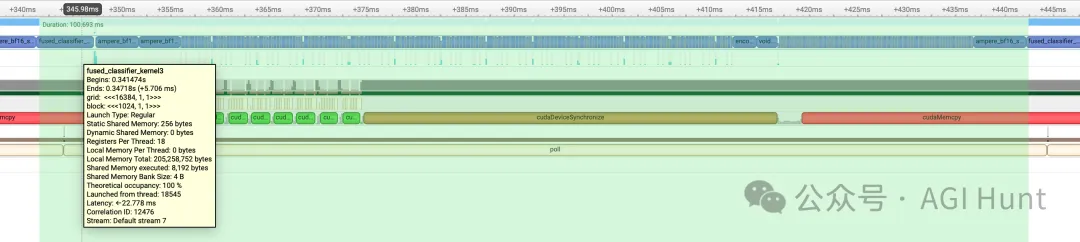
Nsight系统时间线视觉效果,过时1天:
贡献者
- 🧙♂️核心:@ngc92 @ademeure @ChrisDryden @JaneIllario
- 🔥多GPU训练:@PeterZhizhin @chinthysl
- 💎工具:@austinvhuang @Ricardicus @dagelf @rosslwheeler @azret @lancerts
- 🙏讨论和PyTorch支持:@Chillee
值得特别表扬的是@ngc92和@ademeure,他们都非常活跃,并为llm.c项目贡献了大量的代码、想法和专业知识。
值得注意的分支
三个新的值得注意的分支:
-
llm.cpp 由@gevtushenko:这个项目使用NVIDIA CUDA C++ Core Libraries的一个移植
- 这个分支在CUDA MODE Discord Server的这个讲座中被介绍
- llm.zig 由@saimirbaci:这个项目的一个Zig移植
- llm.go 由@joshcarp:这个项目的一个Go移植
特色讨论
LLM.c 光速及以后(A100性能分析) 由@ademeure进行了最近的性能分析,探讨了优化的进一步步骤。
更多关于llm.c的讨论,欢迎加入我们在nn zero to hero Discord的#llmc,或者在目前更活跃的CUDA MODE Discord的#llmdotc。
fp32 CUDA版本计划
我们还将fp32 CUDA代码分离到了自己的文件train_gpt2fp32.cu中,这将只包含纯CUDA内核(没有cublas或cudnn等),我们认为这会是一个CUDA课程的很好的终点。你从gpt2.c纯CPU实现开始,看看你在课程结束时可以通过GPU、仅使用内核和没有依赖关系来加速多快。
细则
所有测量都在以下环境下完成:
A100 40GB PCIe GPU on LambdaUbuntu 22.04.3 LTSNVIDIA driver version 535.129.03CUDA Version: 12.2
llm.c:当前速度约为167K tok/s(今天早上即将合并的SOTA PR上),在master上约为160K PyTorch代码在master上运行速度约为150K tok/s(即我们比150K快约11%) 如果你手动将词汇表大小填充到50304,tok/s会从约150K提高到约156K,将llm.c的速度提升减少到约7%。
注意,为GPT-2在PyTorch中填充词汇表并不是一件简单的事。你必须知道拥有50257的词汇表大小是不好的,它应该是例如50304(它%64 = 0),然后因为令牌嵌入表权重与分类器权重共享,你必须非常小心地屏蔽或以某种方式设置填充维度为-inf,并确保你在采样期间从不使用它们。如果你使用OpenAI权重进行初始化,你还必须进行模型手术。原始的OpenAI GPT-2代码也没有以这种方式填充词汇表。
致谢
感谢Lambda labs为这个项目提供GPU赞助。Lambda labs是我们最喜欢的、去的云GPU地方🙏。














暂无评论内容