
最近scaling law 成了最大的热词。一般的理解就是,想干大模型,清洗干净数据,然后把数据tokens量堆上来,然后搭建一个海量H100的集群,干就完了。训练模型不需要啥技巧,模型结构也没啥好设计的,对算法精度影响很小。事实上,原论文里面讲的逻辑不是这样的。
论文Scaling Laws for Neural Language Models
链接在这里:https://arxiv.org/pdf/2001.08361.pdf
openai于20年1月23放出的论文。里面的核心输出是这样的:对于基于transformer的语言模型,假设模型的参数量为N,数据集tokens个数为D(token数),那么,模型的计算量C约= 6N*D 。模型的计算量C一定后,模型的性能即精度就基本确定。它的决策变量只有N和D,跟模型的具体结构诸如层数、 深度、 attention头个数(宽度)基本无关。相关性非常小,性能(即test loss)在2%的区间内。
Openai发现这个规律后,通过构建一个巨大的海量数据集,然后简单增加gpt模型的深度,就做出了惊人的具有涌现能力的大语言模型。
其实这个规律很好理解的。就是说如果两个人学习力差不多,即模型的参数量差不多,然后题海战术做的试卷题目相当,他们的考试成绩基本接近。因此,对单个人来说,就是多做题目就可以了。
或者换个说法。假设同一条登山的道路,相同体重的人,登到山顶,做的功基本一致。因为重力势能的变化相同。而跟一个人的高矮胖瘦没有太大关系,矮胖对应模型宽短,高瘦对应模型细深。
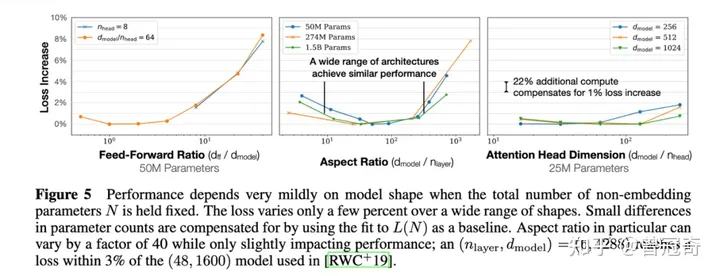
这就是scaling law 的核心内容。如图所示,他测试了不同的head个数,不同的layers深度不同的dmodel大小。对loss的影响很小。后来,这个理论可以推广到非语言模型领域。
误解一:同一个imagenet数据集,alexnet加参数量可以匹敌resnet
Alexnet效果不如resnet,代表的是学习力不同。你加大参数量跟resnet同参数量,效果也会比resnet差。
Scaling law论文有一个非常重要的前提条件,就是都是标准的transformer模型结构。如果不是,scaling law是失效了的。原论文特意做了对比实验。这个可能大家都忽略了。

实验一:lstm模型结构和transformer对比。
如图,左边图中,红色是lstm,蓝色是transformer,横轴是参数量,纵轴是测试loss。可见,同样参数量,同样数据量下,lstm的loss和transformers的loss差距还是很大的。
实验二:标准transformer跟recurrent transformer对比
Recurrent Transformers你可以理解为lstm+transformer,作为一种重点关注于解决长距离依赖(Long-Range Dependence)问题的Transformer架构,主要通过添加对过去状态或过去隐层状态的循环连接(Recurrence)实现。通过这种循环链接,模型理论上能够捕获到更大感受野内的输入信息,从而也更有可能建模这种长距离依赖关系。因此,Recurrent Transformers一般拥有更强的长序列输入处理能力和相对较低的计算开销,在一系列包括长序列文本、图像、视频、甚至深度学习等等领域的任务上有着更大的潜力。
代表作有2019年的ACL Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context。
论文地址:https://arxiv.org/abs/1901.02860v3
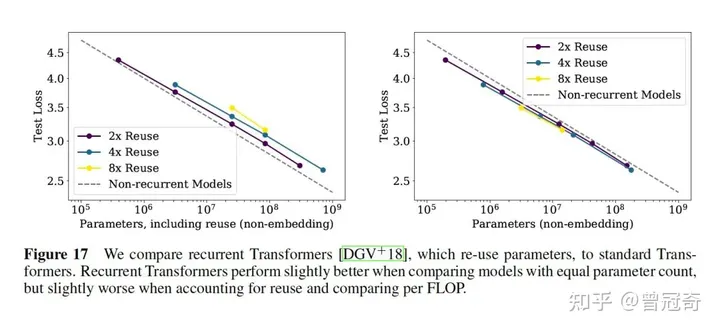
实验结果表明:标准transformer和recurrent TR比,相同参数量大小下,后者比前者有微弱优势,相同计算量(FLOP,浮点计算数)下,前者比后者要好一点。因为相同参数量下,recurrent TR增加了循环计算量。
误区二:对大模型来说,模型结构优化没有意义
我一直觉得scaling law对应的是傻大黑粗的暴力做法,他增加大数据量是对的,但只增加模型深度增加模型参数量,这个事情其实不够灵巧。第一次做实验探索未知是可以的,但往后走,肯定是更加灵巧的模型有经济价值。因此,如何降低计算量,构建一个小型轻量化的模型,例如1B大小,也能达到10B的效果,那这个对于模型真正工程化落地部署具有划时代意义。
模型大,部署成本贵,然后就是达不到实时的效果。例如搜推广,一个接口必须在200ms内返回排序结果,如果你一个简单的大模型都需要1s的响应速度,那么大模型真正落地到互联网信息排序领域是不行的。因此,一味的将scaling law 奉为圣经还只是AGI探索的初级阶段。下一个阶段应该是如何设计更好的精巧结构小模型打败大模型。这个是有可能的。因为Multi-head这一块,有太多冗余计算了。同时它也不够关注长上下文依赖。
















暂无评论内容