1 个小时前
马斯克开源了 Grok
开源声明里说了什么?
配置方法:帮助用户快速启动模型。
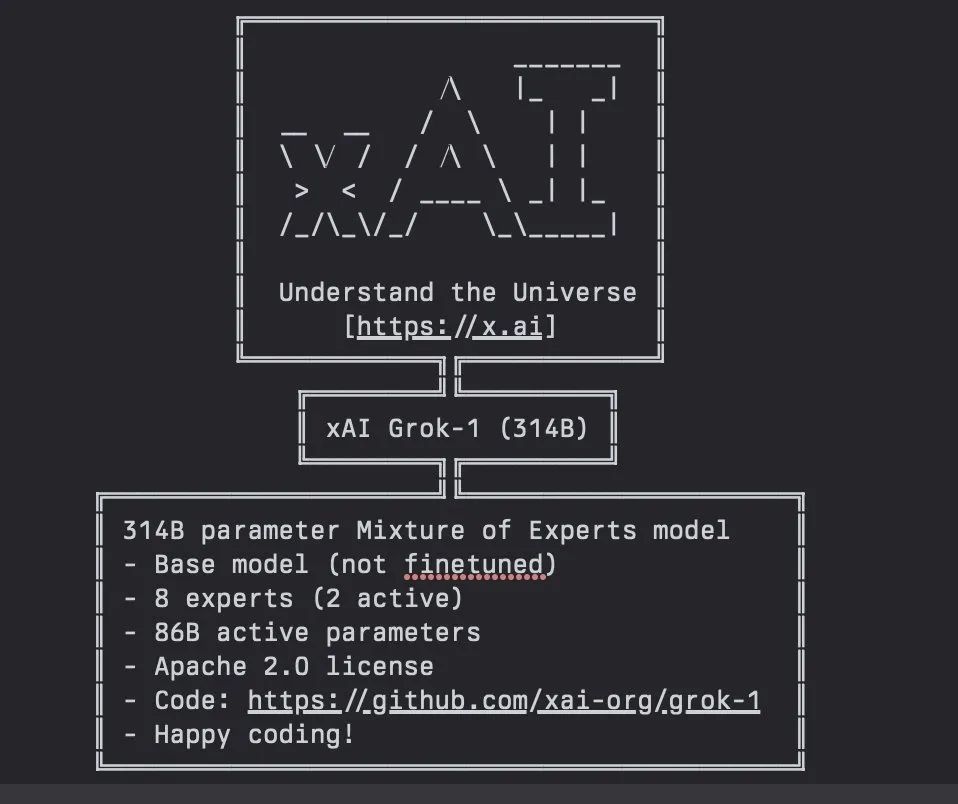
模型介绍:314B 大小,MoE 层的实现并不高效,这样是为了避免自定义内核,以简化模型验证的过程。
磁力链接:用户可以在这里下载模型。
遵循 Apache 2.0,即:
可商用:用户可以自由地将软件用于商业目的,不必支付许可费。
可修改和分发:用户可以修改源代码,并且可以在修改后的软件上施加同样的许可证进行再分发。
专利授权:该许可证自动授予软件用户任何专利权利,这意味着贡献者不能对软件用户提起专利诉讼。
保留版权和许可声明:在分发软件或其修改版本时,必须保留原有的版权声明和许可证声明。
不承担责任:提供一定的保障,但软件作者或贡献者不必为软件可能引起的任何损失承担责任。
网友的深入分析
推特网友 Andrew Kean Gao 第一时间进行了查验,如下:
I just went through the http://model.py, for this 314B open source behemoth with *no strings attached*.
我分析了 .py 文件,这是一个 314B 的模型,并且没有任何附加条款
👇
Basics: 314 B, mixture of 8 experts (2 active) 86B active parameters It’s using Rotary Embeddings #rope instead of fixed positional embeddings
基础信息:314B 的模型,由 8 专家组成(2 活跃状态)86B 活跃参数,使用Rotary Embeddings
Tokenizer vocab size: 131,072 (similar to GPT-4) 2^17 btw embedding size: 6,144 (48*128) 64 transformer layers (sheesh) Each layer has a decoder layer: Multihead attention block and denseblock Key value size : 128
词汇量:131,072 个,与 GPT-4 持平,实际上是 2 的 17 次方
词嵌入维度:6,144(由 48 乘以 128 计算得来)
Transformer 层:64
Key value size : 128
👇
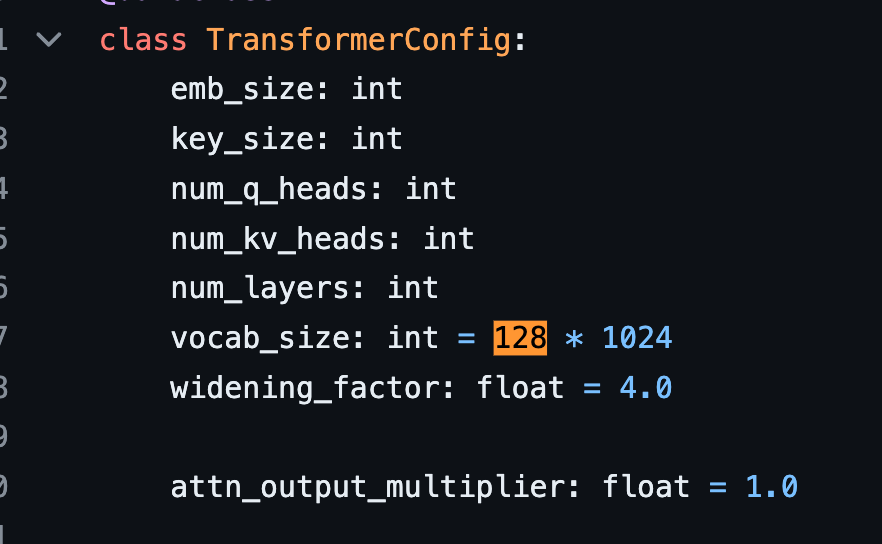
Multihead Attention block: There are 48 heads for queries and 8 for keys/values (KV) KV size is 128. The Dense block (dense feedforward block): widening factor: 8 hidden layer size is 32768 2 experts out of 8 selected per token.
Multihead Attention
查询部分:48 个注意力头
键/值(KV)部分:8 个注意力头
键/值的维度:128
Dense block
扩展因子:8
隐藏层:32,768
每个token,从 8 个专家中选择 2 个
👇
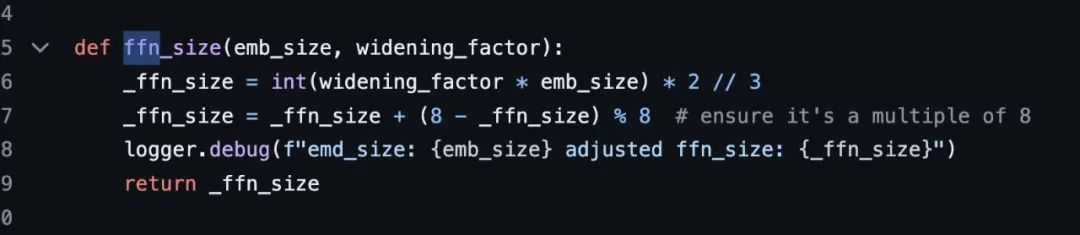
rotary positional embeddings size 6144, which makes sense, it’s the same as the model’s input embedding size Context length: 8,192 tokens precision bf16. There’s something in here about 8bit quantization for the weights
旋转位置嵌入的维度为 6144,这与模型输入嵌入的维度一致,因此这一设计非常合理。上下文长度为 8192 个令牌,计算精度采用 bf16 格式。这里使用了 8 bit 量化
👇
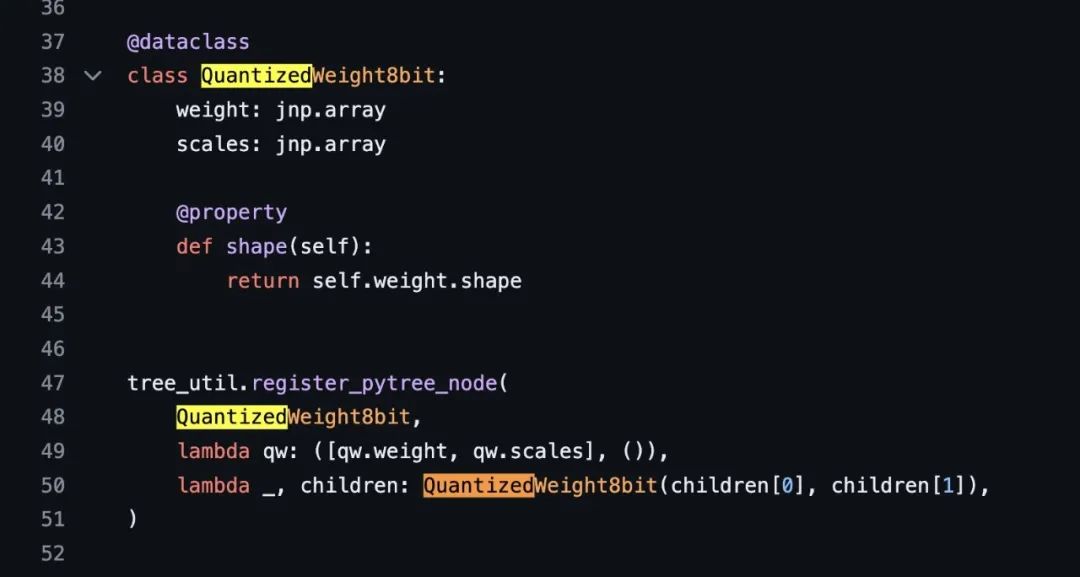
OpenAI 怎么回应?
OpenAI 利用 ChatGPT 的官方账号,第一时间进行了友好互动
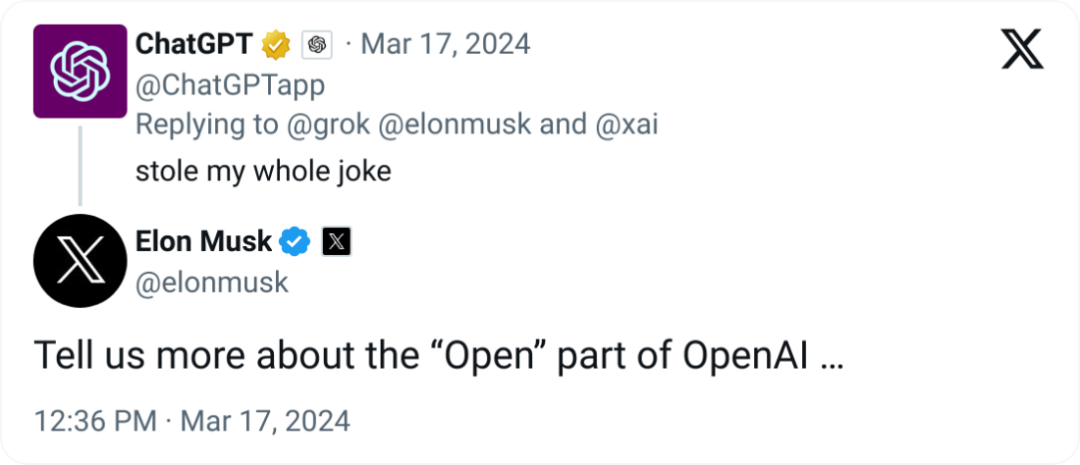
ChatGPT:你干了我干的事(刚刚!OpenAI 把 Grok 开源了!)
马老板:来,咱聊聊 OpenAI 哪里 Open 了
大聪明怎么看?
OpenAI,该起床了!!
















暂无评论内容