
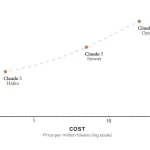
Anthropic震撼发布Claude 3模型,实力碾压GPT-4,引领人工智能新篇章
近日,人工智能领域再掀波澜,Anthropic公司发布了全新升级的Claude 3模型,该模型在多个方面的表现都全面超越了GPT-4。这一突破性进展不仅展示了Anthropic在人工智能领域的强大实力,也为整个...

Max Tegmark AI思想家:AGI不再遥不可及,我们必须停止这种观念
AI领域的思想家Max Tegmark强调,我们需要改变对人工通用智能(AGI)的认知,认为它不再是遥不可及的未来事物。在他的观点中,AGI的发展已经逐渐逼近,我们应该开始着手准备面对它带来的挑战和...



百度错失两次AI机遇:从GPT-1到ChatGPT,错失顶尖人才与行业先机
本文分析了百度在AI领域错失的两次重大机遇,从GPT-1到ChatGPT,探讨了百度在顶尖人才和行业先机方面的缺失。通过对比其他公司的成功案例,本文深入剖析了百度在AI技术发展中的战略失误及其对市...